
Your Data Contracts Are in the Wrong Spot
Why data contracts fail when placed in the wrong part of your data lifecycle


Note from Chad: 👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and I write about data products, data contracts, data modeling, and the future of data engineering and data architecture. Mark is joining me for this article, but I wanted to quickly share that I worked out a deal with O’Reilly so that people can download our upcoming book for free on our website. Follow the link below, and you will get access to the early-release chapters. People who sign up will also receive follow-up emails with updated PDFs with new chapters until the book’s full release.

The Data Contract Implementation Trap
Most data teams are placing their contracts in exactly the wrong spot. You’ve probably heard the rallying cry: “Data contracts will solve our quality problems!” Teams rush to implement them, often dropping a contract somewhere in the middle of their data pipeline for an important data asset downstream, and then wonder why their data woes persist.
The problem isn’t with data contracts themselves. It’s with how we think about where they belong in the data lifecycle. Simply put, many data teams only have control of downstream systems; thus, they try to move quickly by placing contracts where the data team can implement them themselves.
While this may resolve issues between the analytical database and the data team’s consumers (e.g., dashboards, analytics, etc.) initially, it’s only a band-aid solution if you never prevent bad data from being written in the first place. Time and time again, we’ve seen these implementations fail once the upstream changes mount. What was originally believed to be a preventative solution soon becomes a bottleneck, as contracts now flag constant issues or, worse, block the flow of data (remember, timeliness is a data quality dimension!).
In other words: “Pick your poison…”
Have no data contracts in place with unknown errors impacting consumers.
Have data contracts in place that flag and block errors reaching consumers, but ultimately bring downstream data to a grinding halt.
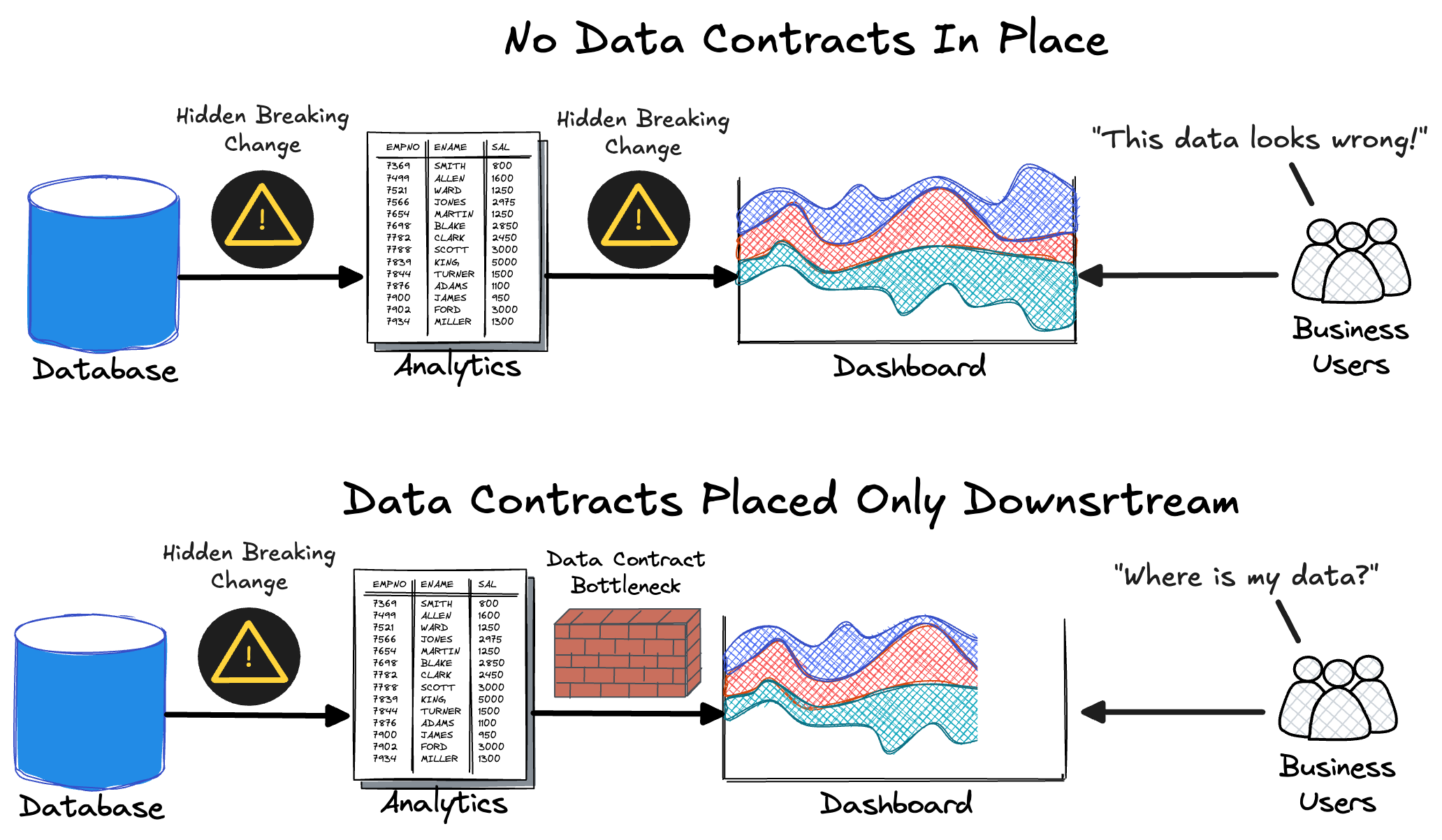
The Illusion of Control
We can abstract this issue as “first mile” and “last mile” data quality. Both are very important, but data contracts are best suited for one of them (hint: first-mile).
First-mile data quality isn’t about your analytical database. It starts at the source systems where raw data gets generated, transformed into usable formats, and shipped to storage. Think of it as the extraction and initial processing phase.
Last-mile data quality begins when data lands in your analytical systems, where data analysts and scientists transform it into consumable data products.
Most organizations focus exclusively on last-mile data quality. They wait until data reaches their warehouse, then attempt to identify problems after the damage is already done. This approach misses countless opportunities for prevention at the source.
The unfortunate reality is that quality issues don’t start in your data warehouse. They start in the code that generates your data. When a software engineer modifies business logic through code, the data written to the database changes accordingly.
The image below is from our book, Data Contracts: Developing Production Grade Pipelines at Scale, and illustrates this flow from code to data.
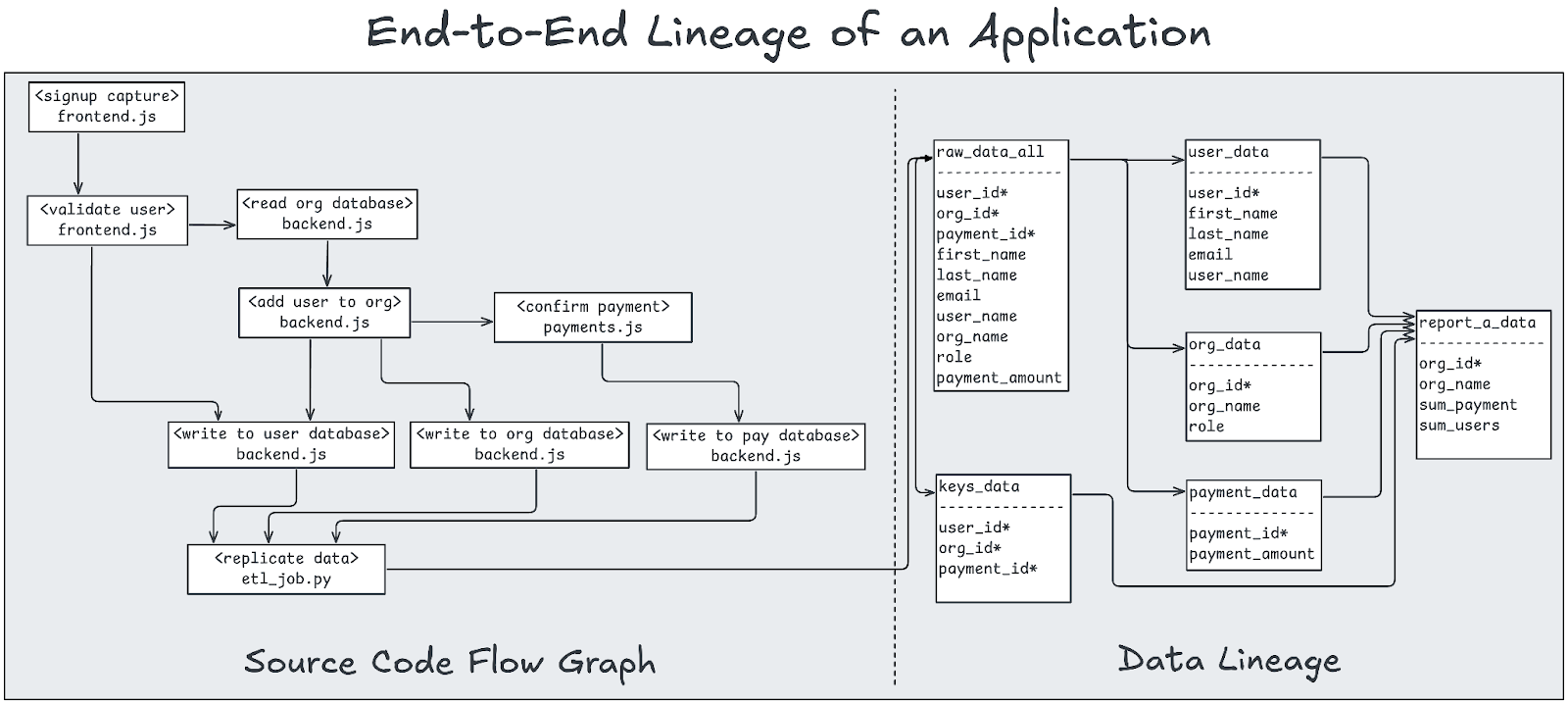
Thus, we argue that many data teams have an illusion of control when they only place data contracts downstream. While you can theoretically protect your transformation logic downstream with data contracts, you still don’t control the root of the problem: upstream code.
The Code-First Data Quality Paradigm
Data quality management can’t succeed by only looking at materialized data. When you focus exclusively on the output, rows, and tables in your warehouse, you’re managing the symptoms, not the disease. The real decisions about data quality happen in the codebase where software engineers define the rules for data generation.
A code-first data quality paradigm requires managing quality across three layers simultaneously:
The codebase that defines data logic
The in-transit systems that move data
The at-rest storage where data lives
This means your quality tools need to understand application code, not just SQL queries. They need to catch problems in pull requests, not just in production dashboards. They need to prevent issues before they materialize, not just alert you after the damage is done.
Instead of asking “What’s wrong with this data?”, start asking “What’s wrong with the code that produces this data?” Instead of fixing data quality issues reactively, prevent them by managing the source of truth where quality decisions are made.
The Enforcement Reality Check
Even when teams recognize they need upstream contracts, they face a harsh reality check—enforcement complexity.
Creating a few data contracts is straightforward. Enforcing it consistently across your entire technology stack is where most initiatives die.
The enforcement challenge spans multiple layers:
Layer 1 - People: Data contracts address a socio-technical problem, not just a technical one, so you need to do the work of aligning leadership and teams on this cultural change regarding how software is developed.
Layer 2 - Adoption: Even if people are bought in, their support will quickly fade if you don’t obsess over making onboarding as easy as possible (you are trying to reduce their pain, not create more work).
Layer 3 - Tech Sprawl: Each tool, database, and code language represents another integration that you must manage; teams that fail to account for this are hit hard with operational pains later.
Layer 4 - Contract Versioning: As your data product evolves or you refine assumptions, your data expectations will change. Therefore, you need to version your contracts over time and ensure they align with the correct historical deployment (e.g., contracts on staging vs. production).
Layer 5 - Alerting: Blanket alerts that are not relevant to the person receiving them ultimately become ignored, risking the entire data contract rollout's success.
Most teams underestimate this complexity by orders of magnitude. They build a contract specification, maybe add some basic validation, then wonder why adoption stalls and violations keep happening.
You Understand Why You Need Upstream Contracts… Now What?
You may find this daunting if you are a data professional reading this and having your “illusion of control” shattered. Thankfully for you, we have gone through this reckoning ourselves and have some clear steps for you to continue moving forward and ensure your implementation is successful in the long run.
If you are starting from scratch, we highly recommend Mark’s article, "The Data-Conscious Software Engineer" (and accompanying conference talk), as a starting point to identify champions in the upstream organization and help you navigate working with your engineering colleagues.

If you already have your key stakeholders in place and are moving towards the planning of your data contract implementations, then we suggest being more strategic. It would be a huge mistake to simply rush to get a single contract out without thinking through how it sets up subsequent implementations.
For context on its importance, we devoted Part III of our book to this entire subject (~100 pages), as it has been the largest friction point we’ve seen across dozens of implementations. While we can’t cover the entirety of this in a single blog post, there is one concept that is central to the adoption playbook: Steel Threads.
Steel threads is a concept that identifies the slimmest use case of an implementation that traverses the entire software and data system(s). This ensures you avoid building point solutions without the means of being adopted elsewhere in the organization.
We highly recommend Jade Rubick’s article Steel threads are a technique that will make you a better engineer if you want to learn more (we cited this article in the book).
Furthermore, this use case should be associated with the most critical data products experiencing quality issues. This increases the likelihood of having a major issue prevented in a meaningful and public way across the larger business.
Your Data-Code Quality Revolution Starts Now
The organizations winning with data contracts aren’t the ones with the fanciest tools or the biggest budgets. They’re the ones who understand that data quality is an upstream problem, not solely a downstream one.
Start with your most critical data product. Trace it back to its source systems. Identify every transformation point. Map every handoff. Then begin layering contracts from the source forward, creating an unbroken chain of quality assurance.
Don’t try to boil the ocean. Pick one pipeline, implement contract-driven quality end-to-end, and prove the value. Then expand the approach to your next most critical data product.
The transformation occurs when your software engineers begin to consider data quality as part of their development process, rather than something that happens a few degrees of separation from their code after they’ve completed it.
We argue that the question isn’t whether you need data contracts. It’s whether you’re ready to implement them in a way that actually works.
Good luck!
Great article and awesome to see you guys on Substack. I ended up implementing Data Contracts at my robotics start up role, leveraging GCP. It was a great/challenging experience.
To your point, it required huge amounts of socio-technical work. Namely breaking through SWE's skepticism on why we needed it. Thankfully I had 3 schema drift nightmares I could put on paper for them.
Put it all here: https://thefulldatastack.substack.com/p/proposing-and-implementing-data-contracts
Love this!