
The Data-Conscious Software Engineer
The Unicorn That Data Teams Actually Need

This article extends the ideas presented in Chapter 10, "Change Management: The Crux of People, Process, and Technology," in our upcoming O’Reilly book. As of this article's posting, Chapter 10 is now available in the early release version of the book, which you can download for free at this link (or here if you prefer an unbranded but paid version).

Do Data Teams Need SWE Best Practices?
Before you get your pitchforks, the answer is a resounding yes to this question, but I’ve recently changed my opinion on how data teams accomplish this. Something I prided myself on early in my startup career was being a “full stack data scientist,” where I felt comfortable not only developing models and analyses but also having the ability to put them into production as data products. I saw the tremendous impact it had on my career growth and on the teams I worked with, and thus, I pushed hard for any data professional to upskill as a means to bridge the gap between software and data teams.
However, I overlooked one caveat when thinking my situation could be applied to others– software engineering teams often don’t trust the code written by data teams (the irony of a data scientist falling for selection bias). In hindsight this was obvious even for my own situation. For example, in my last startup role, it took me over a year before the engineering team trusted me with read/write access to the transactional database. Other clues included engineers saying things like, “Oh, you created unit tests... Nice!” in complete shock that someone on the data team could write production code.
While frustrating at times, it was the right move by those engineers to be skeptical, and I would honestly hold the same sentiment if I were in their shoes. At the end of the day, software engineering teams are the ones held accountable for application uptime, managing the transactional database, and protecting their codebase. Anyone implementing code outside of these constraints is a potential threat to the above, and why, internally, they have so many best practices to prevent issues (e.g., CI/CD, unit tests, version control, etc.). Furthermore, while all SWEs are aware of these standards, it’s more of a spectrum of understanding among the various data roles they interact with.
While I still think data teams need to upskill on SWE best practices, I no longer think engineering-focused data teams are enough to have robust data workflows and bridge the gap between both sides. This problem statement of “improving the collaboration between data and software developers” is what pushed me to devote the last couple of years to data contracts and allowed me to find the missing link.

Lessons From Getting Data Contract Buy-in
Three key friction points emerged in the past two years of working with dozens of companies exploring data contracts and researching various implementations for our upcoming book:
First, data teams who thought they could only implement data contracts downstream in the databases they controlled were not set up for success. While the ease of implementation on their own analytical databases is enticing, it’s not resolving the root issue: the data entering the database is unexpectedly changing and breaking their downstream assumptions. What results is the data still being bad, this bad data being bottlenecked without means to resolve the root issue (data timeliness is still a data quality dimension), and there is increased complexity of managing data contracts without its full benefits.
Teams who are pursuing this path are typically under extensive pressure from their own downstream business colleagues who are losing trust in the data provided to them. Thus, data contracts often look like a lifeline to prevent bad data from being received by their now-skeptical business stakeholders. For teams in this situation I actually advise against data contracts and instead suggest pursuing data observability instead (check out my talk on data contracts vs observability to learn more). Teams who pursue the data contract path instead often come back six months later, ready to focus on upstream systems managed by software engineers.
Second, many data teams were often hesitant to talk to their upstream engineer colleagues. One of the first questions I ask data teams interested in pursuing data contracts is, “How is your team’s relationship with upstream engineers?” Their answer serves as a litmus test of how difficult getting buy-in for data contracts will be. Furthermore, if the answer were “not good” or "limited," an extra step of building a case for collaboration between data and software teams would be added to the timeline (sometimes this friction is insurmountable). To be clear, it’s not that these teams don’t want to work well with each other, but rather their scope and constraints are vastly different and thus make it difficult to do so without intentionality (I’ve discussed this disconnect in depth in a previous article: OLTP vs OLAP: The Core of Data Miscommunication).

Third, nearly every time we brought up data contracts to engineering teams they would say something along the lines of “Wait!? The data team is not already doing this!?” There are two facets to this response:
a) Engineering teams expect that these constraints already exist for data teams.
b) Software engineers underestimate how hard this task is for data compared to code.
Software engineering teams that heavily leaned into the latter category of “underestimating” often believed the pains presented by data teams could be resolved with only unit tests. Similar to the data teams that thought the problem could be resolved by placing data contracts only downstream, focusing only on unit tests doesn’t address the root of the problem data contracts address: it’s not enough to understand that a breaking change happened; you also need a means to enforce expectations and manage the change across impacted parties.
Despite these challenges, there was one similarity among the teams that overcame or completely avoided these friction points– someone within the software engineering organization had a nuanced understanding of the relationship between software-data workflows AND became a champion for supporting data teams because they recognized the impact of data to the broader organization.

The Missing Link: Data-Conscious Software Engineers
Returning to my original question of whether data teams need SWE best practices, again yes, but it’s not enough. Data teams also need data-conscious software engineers to champion their work in being properly integrated with the software organization. While it may be easy for organizations to point to data engineers to fill this role, the reality is that data engineers are not beholden to the same constraints as software engineers. This became even more apparent when I spoke to data leaders ranging from VPs to CDOs, who made it clear that data is a second-class citizen in respect to budget allocation.
Specifically, data organizations’ budgets were often not its own line item but rather seen as a highly expensive cost to the IT organization. Even worse, I once talked to a CDO whose own CEO didn’t realize all the important work the data team was doing until this CDO’s own exit interview! It wasn’t for lack of trying, but rather, while it’s easy to draw the line between software and its impact on revenue, data is often a black box to executive leadership. Hence why the data-conscious software engineer becomes critical in surfacing the needs of the data team to the leaders that have the most control over budget allocation (i.e. IT).
With that said, it’s not enough for software engineers to be aware of data (they already all work with data), but instead they need to be "conscious" or “painfully aware of; sensitive to.” The major emphasis is the word “pain,” where the data-conscious software engineer understands how the lack of data management will cause pain not only for the data team but also for their software engineering colleagues and the business as a whole. Unfortunately, I think this data-conscious software engineer is currently a unicorn… for now.
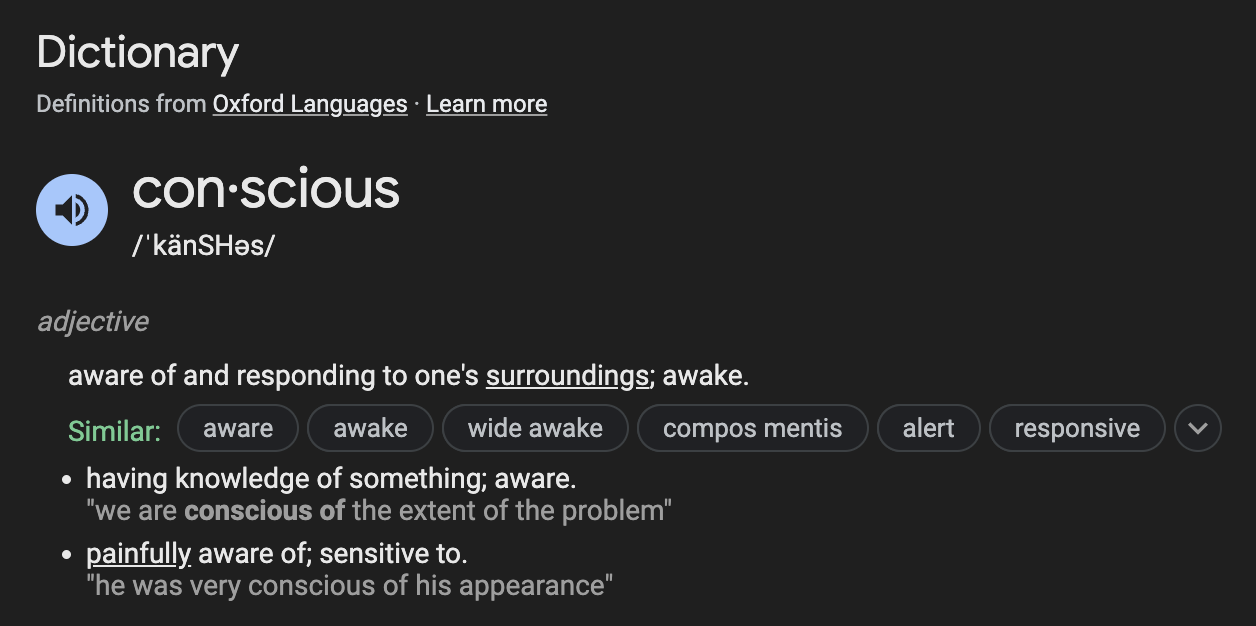
Specifically, any data engineer who has taken over a database built initially by software engineers has seen untold data horrors (I’m looking at you NoSQL). But it goes both ways, as data and software skills overlap in a matter where each respective side knows enough to be dangerous. In addition, while data professionals are encouraged to learn software best practices, software engineers don’t have the same incentives to learn data best practices, and thus, rightfully don’t prioritize it. Furthermore, many software engineers’ relationship with data is only ever interacting with it as a means to an end or a byproduct of their code rather than the valuable asset itself. This made sense when data was primarily used for reporting and analytics, but I see this shifting relatively soon with the rise in prominence of data products (e.g. ML Models, LLMs, Data as a Service, etc.) among all businesses beyond tech.
With this shift, I argue that we will not only see the rise of the data-conscious software engineer, but also see the persona move from being a unicorn to a required member among software engineering teams. Among the data-conscious software engineers I have encountered over the past two years, I have seen the following five key characteristics:
1. They are often staff-level or above where their scope oversees the wider architecture of the business and thus have the purview of how software and data intersect in meaningful ways.
2. They have been part of a data team or deeply involved in a major data initiative (e.g. building a data platform) where they took ownership of the handoff of data between software and data teams.
3. Despite their deep involvement in data, they recognize it’s not their area of expertise and thus rely on the specialized knowledge of data teams (e.g. data engineers, scientists, analysts, etc.).
4. They view data as a product within the organization, and they seek ways to maintain this data in the same fashion they maintain the software they oversee.
5. Leadership views these individuals as “special ops” who are often moved to different units within the organization to create structure and fix the most challenging problem areas of the codebase and or organization.
While this persona is a unicorn today, I imagine they are hidden within your very own organization without anyone realizing it. If I were on a data team considering data contracts, I would highly prioritize finding a software engineer with the above characteristics and building a relationship with them. They could potentially be the missing link to improving data utilization within your organization.
Yet another brilliant surfacing of the people/process constraints in our data community. It seems like DataMesh is built around that foundational consciousness raising that your data-conscious SWE brings.