
The True Cost of Data Debt
TL;DR It's Trust


Mark here, and I’m taking over for this newsletter edition to share some of the ideas in Chad and I’s upcoming O’Reilly book on data contracts. One of the main topics we discuss in the book is the role of data debt and how data developers are different from software developers. We welcome any feedback in the comments, as we are constantly iterating on our ideas!
Data is Not a Resource
Treating data like a mere resource sets companies up for failure, as data is viewed as a means to an end for the organization. Just numbers for rarely viewed dashboards, just requirements for CRUD operations, or just a cost of running a business. Yet this perspective misses three significant attributes of data:
Data is an asset rather than a resource.
Not all data is of the same value.
The value of a data asset changes over time.
Coupled with the reality that data is in a constant state of decay, without efforts to maintain your data asset, it will slowly decrease in value. As an analogy, we can compare the “asset” of data to the asset of real estate. While the initial asset holds inherent value, it requires additional effort and upgrades to increase the value and make a profit. The opposite is also true, and much more powerful, as I’m sure you have seen the swiftness of disarray setting in among abandoned properties.

Similarly, data will slip into disarray, resulting in the all-too-familiar scenario of data engineers rushing to reactively put out fires rather than creating value. This is what we call “data debt,” or the outcome of incremental technology choices made to expedite the delivery of a data asset like a pipeline, dashboard, or training set for machine learning models.
Note: I highly encourage checking out this excellent article The best way to explain data governance to beginners, by Willem Koenders, that takes this analogy even further.
Technical Debt vs. Data Debt
You may be thinking, “But wait… we already have the term technical debt! Do we really need a separate term for data?” I respond with an emphatic “yes” to this question for the following reasons:
SWE’s Have Different Constraints: Technical debt is a well-established and talked about challenge through the lens of software engineering. Specifically, it emphasizes how one can realize short-term gains by shipping software faster, at the expense of lower-quality code that ultimately slows development in the long term. While this does impact data developers as well, our constraint is not the ability to ship code. Our constraint is the ability to provide insights through an iterative process with expected dead ends.
Garbage In Garbage Out: An organization can have the best ML models, the greatest developer experience, and a streamlined production process– but throw garbage data into this pristine system, and you will still get garbage results. It’s why major tech companies can build products at a worldwide scale but still struggle with data quality.
Silent Failures: Software developers absolutely experience silent failures, but I would argue that silent failures in data are much more prevalent and dangerous than in software. A large part of this difference is that software engineering best practices are much more mature and universally accepted among organizations (e.g., unit tests, CI/CD, etc.). A great example of this is the company Bird, who overstated shared electric scooter revenue for two years due to a data quality issue… not a technical issue.
If you want to learn more, Chad goes into greater detail about the difference between software and data developers in his previous article Data is not a Microservice: Why Software Engineering Can't Solve Data's Problems.
The Modern Data Stack’s Prisoner Dilemma
Despite having so much knowledge about technical debt from the software landscape, how were we not able to apply such lessons to data and its differences? Three words: Modern. Data. Stack. (article describing the Modern Data Stack)
While data professionals love to argue about the best data tools, we can all agree that most organizations are a dumpster fire regarding their respective data. But it wasn’t always this way. Talk to any data industry veteran, and they will share their frustration with seeing the best practices, such as data modeling, move from standard practice in the 90s and 2000s to a lost art from 2010 to the present. How? I argue that the rise of cloud computing enabled cheap data storage that can scale quickly, thus opening the market for managed cloud data services, also known as the Modern Data Stack.

This is not to say that the Modern Data Stack is inherently bad. Quite the contrary, the Modern Data Stack instead enabled the rapid adoption of advanced data workflows beyond enterprise companies. It’s an important era in the growth of our industry, and it has created a market paying many of our salaries.
Where our industry made a mistake with the Modern Data Stack was having it become the default stack for companies adopting data practices. In conjunction with the peak hype-cycle of data science, best represented by the 2012 article Data Scientist: The Sexiest Job of the 21st Century, companies found themselves in a prisoner's dilemma: adopt data science and potentially realize tremendously high gains or don’t adopt data science and potentially watch your competitors outpace you via data.
The Modern Data Stack provided companies facing such a dilemma an onramp into data science that was both quick to implement and initially very cheap. Unfortunately, it also gave companies enough rope to hang themselves if they weren’t careful. Companies who understood the tradeoffs of the Modern Data Stack identified how data fit within their unique business situation and managed the increased complexity within their system. Companies who didn’t found themselves overwhelmed with spaghetti SQL, paying a large cloud bill, and being deep in data debt.
Chad and I go into more detail about this on a panel at the 2023 MDS Fest conference.
How Data Developers Deal with Data Debt
There are a plethora of traps companies can fall into with data debt. While not exhaustive, I believe the following five forms of data debt are common:
Data consumers navigating multiple sources of “truth” with respect to data assets (e.g., different ways to calculate revenue)
How the business drives revenue changes, such as new products, and thus, the data loses parity with the business needs unless new mature data assets are generated.
Data is arriving late to data consumers either due to inefficient pipeline speed or broken data pipelines.
There is a misunderstanding of the semantics of the underlying business logic, resulting in generating bugs through data transformations.
Understanding complex data lineage, such as an overwhelming number of dbt models that are redundant and hard to manage.
These challenges are expected as an organization grows in data maturity, and thus, developers resolve these data quality issues in the following ways:
Reactive and Manual: Companies early in their data maturity can leverage data but lack the infrastructure to identify and resolve data quality issues automatically. Thus, data developers manually review data for errors by viewing raw data, comparing table aggregates, and tracing data lineage. In these environments, data quality is seen as a luxury, and the data team leverages these painful instances into buy-in for improved infrastructure. (I detail these tactics in this 60+ page document.)
Data Governance: As the company scales, data governance provides the necessary constraints to mitigate the risk of degrading data, access control of data, and ensure data meets regulatory requirements (e.g., GDPR). This is especially true among enterprises where mitigating risk due to data use can prevent millions of dollars in fines.
Data Observability: This is often a great first step in getting a benchmark of your current data state by monitoring data cleanliness, SLAs, and even statistical tests to catch data drift. I previously interviewed Christopher Berg on the topic, who described it perfectly, “[Observability] first, get the information, stick a bunch of thermometers all over your data pipelines, your models, your viz, measure all that stuff. Then, look at the data and say, ‘Where are the bottlenecks? Where are the errors?’”
Data Contracts: Chad speaks about data contracts heavily in this newsletter, so I won’t repeat him here. But, I do want to call out how we see data contracts fitting within the larger data quality toolbox. While data observability is excellent for surfacing unknown data quality instances (e.g., silent failures), it cannot prevent data quality issues. In addition, while data governance establishes the constraints of data utilization within the organization, it cannot enforce these constraints. Data contracts enable the prevention of known data quality issues and enforce constraints.
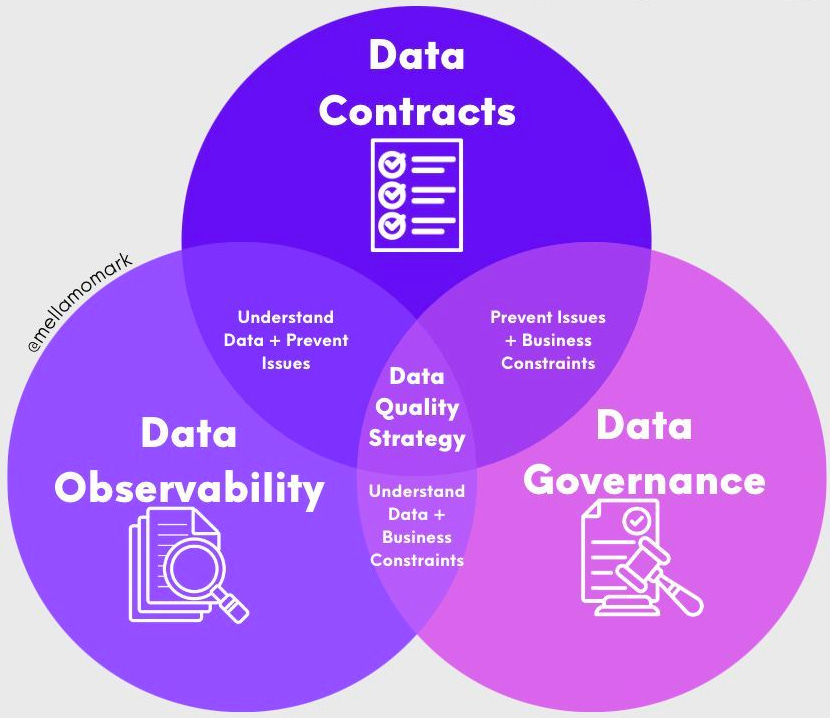
Individually, these components of data quality tooling provide value, but we strongly believe that the addition of data contracts with these tools creates a system where the whole is greater than the sum of its parts.
The True Cost of Data Debt
While we can’t share the entire chapter, our publisher has given us permission to share small paragraphs here and there from our data contract book. This section from our book describes the cost of data debt best:
“Data debt is a vicious cycle. It depreciates trust in the data, which attacks the core value of what data is meant to provide. Because data teams are tightly coupled to each other, data debt cannot be easily fixed without causing ripple effects through the entire organization. As data debt grows, the lack of trustworthiness compounds exponentially, eventually infecting nearly every data domain and resulting in organizational chaos. The spiral of data debt is the biggest problem to solve in data, and it's not even close.”
This resonates with me significantly due to my first data science job, where I learned the hard way the value of data trust. In that role, I supported the sales team with early-stage leads in the pharmaceutical research space. Part of my job was to profile our data assets to inform if our data could support clinical research or analyze drug markets. I completely misinterpreted a key data assumption, which resulted in the sales team presenting the wrong data to one of the largest accounts in our pipeline. That misstep resulted in me spending months regaining the trust of my sales colleagues, and some still questioned my work.
It was a very hard lesson on data trust, but it was one of the best things to happen to my data career. In my next data science role, I vowed not to make that mistake again and prioritized data trust over everything else. This was integral in becoming a valued resource to leadership and having my data skills utilized for key decisions of the business, as my colleagues knew I did my due diligence and kept them informed of data limitations.
While my personal example is on the scale of a single job, the importance of data trust is exponentially higher at the organizational level– it can be life or death for a business and or product. For example, Bird’s data quality blunder may lead to bankruptcy, Zillow Offer’s data misstep cost them $500M, and Epic’s wrong use of data for their sepsis model resulted in lost credibility. Thus, organizations don’t need to focus on scaling their data infrastructure— they instead need to focus on their ability to trust their data as they scale.
Excellent article!