
The Production-Grade Data Pipeline
And Why Tech Debt Accumulates Without Them

👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and I write about data, data products, data modeling, and the future of data engineering and data architecture. The newsletter just passed 4K subscribers! Thank you to everyone new and old. In today’s article, we’ll be talking about the differentiation between Prototype and Production-Grade Data Pipelines. Please consider subscribing if you haven’t already, and be sure to reach out on LinkedIn if you ever want to connect or chat.
One of the largest impediments to addressing data quality at any organization is the lack of collaboration between data producers and data consumers. I wrote about this challenge in Data’s Collaboration Problem. A common workaround to missing collaboration is the rise of CDC/ELT and the proliferation of non-consensual APIs. Can’t get a software engineer to emit the data you need to solve some business problem? Connect your ELT tool to a production source and extract a batch JSON dump on a schedule. Easy (Until things start breaking…whoops).
The second largest impediment to addressing data quality is the lack of collaboration between consumers. Data teams that ‘own’ core business objects leverage tools like dbt to quickly spin up data models to answer an endless stream of questions about feature performance. In a start-up’s youth, these data models are often written by an analyst, data scientist, or underwater data engineer running from one fire to the next.
So what’s the problem? Without a central authority like a data architect or governance committee driving thoughtful design, these domain-centric data models are rarely constructed in a manner that is trustworthy, scalable, well-documented, or even understandable.
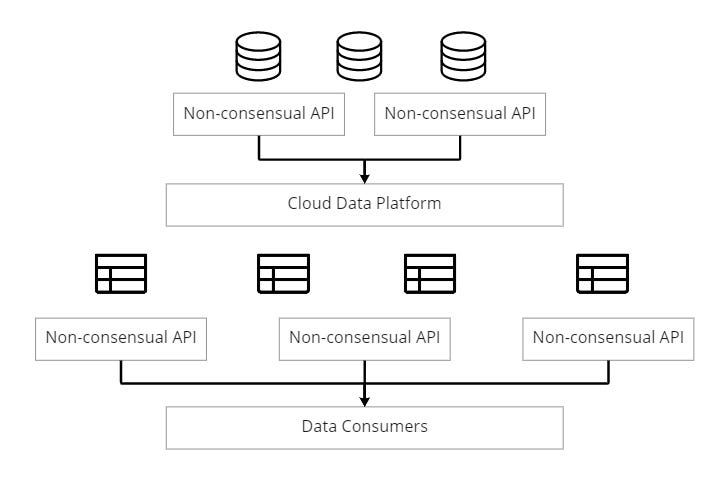
This leads to two levels of data quality issues: First, from data producers to data consumers as data is unexpectedly changed, schemas are broken, and regressions are introduced. This data was never intended for analytics and ML in the first place and thus lacks validation, monitoring, and documentation. Second, the same issues arise from data consumer to data consumer at the table/view level. Teams build datasets for their own use cases ignoring how the entire business will eventually consume these datasets. Documentation, monitoring, and clear accountability are shelved for later.
However, just because a pipeline isn’t robust does not mean it fails to serve a function. In the early days of a new data product’s existence, exploration is important. Both the product and our understanding of the business are actively changing. Taking strict contracts against data that may not be useful presents producers with an undue burden of quality management. Data consumers still need the freedom to explore and experiment without limiting their producer counterparts.
Prototype Pipelines vs. Production-Grade Pipelines
All data pipelines should fall into one of two categories: Prototypes or Production-Grade.
Prototype Pipelines are not production-ready. The data should not be leveraged by external consumers for trustworthy data. A prototype pipeline is most frequently comprised of modern CDC/ELT, data models that don’t necessarily have clear ownership or documentation, and non-scalable SQL. It is primarily used for data exploration, answering directionally correct ad hoc questions, and rapid iteration on data products. The focus is speed and flexibility.
Production-Grade Pipelines are the more mature, reliable older brother of prototypes. The data can be depended on by external consumers. The data is collaboratively defined and well-modeled. A contract between producers and consumers ensures that errors won’t be introduced from production systems, and if they are it is a high priority to fix them. Expectations are set by consumers in order to catch regressions which can then be triaged by upstream teams. DataOps best practices are followed with clear change management, monitoring, documentation, and alerting.

Prototype and Production pipelines are positioned at opposite ends of a spectrum of use cases. Data consumers must use their best judgment to determine when a pipeline is ready for production, and when it can afford to remain a prototype. A good rule of thumb is that a pipeline should be production-grade if data quality meaningfully contributes to the pipeline’s ROI.
While the middle of the spectrum can be murky, the tails are clear. Financial reporting, AI/ML, and core semantic concepts leveraged by the entire company require production-grade pipelines, whereas exploration and dashboards for one-off ad hoc questions most likely do not.

The Production Grade Pipeline Workflow
Production Grade Pipelines have several components which differentiate them from Prototype Pipelines. Teams are not required to implement each component or implement components sequentially for a pipeline to be production-ready.
Collaborative Design: Building the right data model, together
Contracts: An agreement between producers and consumers to vend data under a certain standard with certain change management policies
Expectations: Assert what data is expected from an upstream source and flag offenders
Monitoring: Detect errors in production systems and datasets
Change Management: CI/CD, version control, and change communication
Collaborative Design
Unlike Prototypes, Production-Grade pipelines require thoughtful design and data modeling. The goal should not only be to emit high-quality and trustworthy data from the source but the right data in the most ideal data model. While having a full-time data architect to drive the conversation is fantastic, distributed teams of engineers and data developers can collaborate on a single surface to iteratively build out the most meaningful workflow without an official title. A design surface allows the workflow to be flexible, morphing as our understanding of the data evolves.
How to do it free: Entity Relationship Diagrams (ERDs) are excellent tools for data design. You can collaboratively create ERDs for free on tools like Lucid Chart, Miro, or Figma.
The not-so-free option: Ellie.ai. Ellie.ai is a SaaS tool that claims to be the Figma for data. They provide a collaborative surface for building data models, semantically defining data structures and other cool features. Their trial is free so definitely give them a try.

Data Contracts
Data Contracts are agreements between producers and consumers that are used to define and enforce how schema, values, and business logic changes are rolled out, monitored, and communicated. Contracts are a cultural transition and can be managed through documents or APIs. I’ve spoken a lot about contracts, so feel free to dive into more detail in my last newsletter:

How to do it free: Excel or Google Docs are an excellent choice. Data Contracts are agreements that capture what data is needed, a description of each column, and critical information for producers. I also recommend including a testing plan and a set of SLAs. There are no paid contract platforms at the moment.

Monitoring
Monitoring tools allow both producers and consumers to detect patterns in the data volume and shape. Monitoring tools are excellent ways of understanding when and how contracts were violated and can be used to catch unexpected regressions. I recommend Monte Carlo as one of the best paid monitoring tools around. No reason to go free on this one - they’ve solved this problem.

Expectations
Expectations are a necessity for production-grade data pipelines. Consumers can assert what they expect the shape of their data to be, test, and immediately identify violating properties. In many ways, they are the opposite side of the contract- validation tools for consumers to ensure contracts were followed.
The free (and paid) option: Great Expectations is an excellent open-source tool formaanging e2e expectations and the hosted version Superconductive is a highly recommended paid alternative.

Change Management
Change Management refers to the processes related to CI/CD, version control, data diffs, and other tools for producers to manage the evolution of their data pipelines. Change Management is a pretty expansive field (might jump into it in another post) but there are a few standouts worth mentioning.
How to do it free: Worst-case scenario? Git & GitHub get the job done, but more specialized open source tools for pipelines like Pachyderm do exist (though there are also paid options).
The not-so-free option: One tool I really like lately is Datafold. Datafold deals with data quality in the pull request by providing a diff of how data assets will be impacted by code changes. Pretty novel concept!

Summary
OK, a quick recap.
Non-consensual APIs are bad
A Prototype Pipeline has value for exploration, but should not be trusted
Production Grade Pipelines are critical for use cases where data quality makes a difference to ROI
Both Prototypes and Production Grade Pipelines are necessary
Production Grade Pipelines are intentionally designed with contracts
Production Grade Pipelines are an excellent place to apply e2e DataOps
The meat of a Production Pipeline workflow can be implemented for free, but there are existing and developing tools in the space as well
Any Questions?
Write to me! I always like to hear your opinion. In the meantime, good luck managing data quality, and talk soon.
-Chad