
Data's Collaboration Problem
And Why the Modern Data Stack Can't Scale Without Fixing It

👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and every week I talk about data, data products, data modeling, and the future of data engineering and data architecture. I’m still working on the follow-up to ‘The Death of Data Modeling’ Pt.1 (out next week). In today’s article, I will be diving into the need for the return of data design and collaboration - which I think is more important than any new data technology in the Modern Data Stack era!
Tags: data strategy | data products | Modern Data Stack
Last week on LinkedIn I wrote on an issue that’s been top-of-mind for me lately: data collaboration. Here’s the introduction:

The Modern Data Stack is in an unusual place. Tools to emit and manage our data effectively in the cloud, organizational frameworks (Data Mesh, Data Marts, Data Fabric) and modeling techniques like star schema already exist and have scattered adoption. Despite this, the amount of data architectures that leverage all these tools effectively is a rounding error. Even at the most forward-thinking tech companies, the majority of data setups are difficult to manage at best and unscalable garbage dumps at worst.
I have talked to many data teams who are shocked to find their poor data infrastructure is not unique. It is not the result of technical or organizational decisions and it will not be solved by leveraging yet another piece of siloed software. The Modern Data Stack in its current incarnation will not scale. There is a fundamental, foundational problem: Collaborative Design is absent. Without collaboration, the MDS has nowhere to go but headfirst into a brick wall.
How the Modern Data Stack Killed Design
Today, there are many data tools that comprise the ‘Modern Data Stack.’ Such tools are characterized by their simplistic deployment in the cloud, scalability, and component-based nature. Each tool solves a distinct challenge in data, including:
Separation of compute and storage (Snowflake, Data Bricks)
Data lineage (Stemma, Alation)
Transformation (dbt)
Job orchestration (Airflow)
Schema management (Protobuf)
Streaming (Kafka)
BI (Looker)
and many more…

These tools are implemented by data engineers or data platform teams. As pain relating to the data infrastructure stack manifests for data consumers, platform teams search for tooling that can alleviate the pressure. The emergence of this pain tends to follow a typical pattern:
Early data teams pull data directly from S3 for analysis. As the asks for data become more frequent and complex, a need for standardized warehousing and BI infrastructure follows.
Once a Data Warehouse is in place, data teams begin to extract data from a variety of 3rd and 1st party sources for simple aggregation and analysis via ELT tools like Fivetran or Airbyte.
When product managers arrive at the company, they have requirements to understand user behavior in websites and applications. Instrumentation tools like Mixpanel and Snowplow come next. Data is piped from these tools back into the Warehouse.
As the data volumes grow, more robust infrastructure needs emerge. Data engineers enter the fray with a more deliberate data strategy. They set up a core data pipeline infrastructure comprised of cleaning and organizing data coming from ELT/CDC systems and leveraging scheduling/orchestration tools for pipeline development and transformation.
After the number of tables in the Warehouse increases, data consumers begin to struggle to find the data they need, understand the data, and trust it. Data Catalogs, Monitoring platforms, and other governance systems are put in place to help address this.
Even with these solutions complexity and sprawl continue. Data teams spend weeks to months generating feature sets for ML models, creating metrics, running experiments, and data munging. Critical datasets break and lack owners. Data duplication spirals out of control. Teams turn to new approaches like Data Mesh and Semantic Layers for greater visibility and accountability of data assets.
The majority of companies leveraging the Modern Data Stack are somewhere on this journey. Of course, variations exist but after speaking to dozens of companies I have observed the same trends appearing repeatedly. These issues arise in almost all companies leveraging MDS tools whether they are large-scale enterprises or Series B startups.
While the above implementation patterns may seem like a logical progression in technology choices, in reality we are witnessing the gradual emergence of tech debt, bugs, and missing functionality that stems from a misapplication of the Data Warehouse. Modern data teams have forgotten a core principle of data architecture - The Data Warehouse was always intended to be a replication of the real-world through data. By employing collaborative data modeling and thoughtful design in advance, the original Warehouse was scalable, usable, and possessed clear ownership boundaries. The Modern Data Stack solves a variety of engineering challenges relating to cost and performance, however it has regressed 30+ years when it comes to how the data is used to solve business problems.
Manoranjan Titto of Slalom states the problem clearly:

So where did the Modern Data Stack go wrong?
The Problems Big Tech Built
To be fair, the legacy methods of creating a Data Warehouse were slow and bogged down by extensive governance. It required bringing in Data Architects, creating ER Diagrams, heavy modeling, implementing role-based access control (RBAC), and more.
Modern startups simply don’t have that kind of time.
In the harsh VC landscape startups are expected to blitz-scale, deliver 10x results YoY, and ship features faster than you can blink. Insights are requested by executives, product managers, and analysts well before the first data engineer has ever been hired. The cost of applying old-school Data Warehousing principles so early in the product validation process is not feasible.

That explains why modern tech companies have gravitated away from traditional Data Warehouse design, but it doesn’t explain how we ended up in the mess we are in now.
I put at least part of the blame on Big Tech. As much as we idolize famous engineering-first companies, the problems these top .001% businesses face are not the same as the rest of us. Google and Meta's primary data issues revolve around cost. Enormous data volumes, real-time computation, experimentation, and other use cases mean that performant databases are worth their weight in gold. After engineers solved these problems within Big Tech, the rest of the industry raced to copy them without being thoughtful about their unique data needs.
At Convoy, we have comparatively low data volumes but radically higher data complexity. Convoy collects data across many different types of entities: carriers, shippers, shipments, offers, RFPs, simulations, brokers, bids, and over 100 other critical objects. These entities interact with each other in ways that are not always clear or linear. Business rules change frequently, and as products are added we discover new relationships or real-world actions we'd like to record with high quality. Simply capturing this semantic data in a discoverable manner was so critical for us that we invested in an internal tool (Chassis) to help teams record and search for service-level events, their schemas, and event metadata.
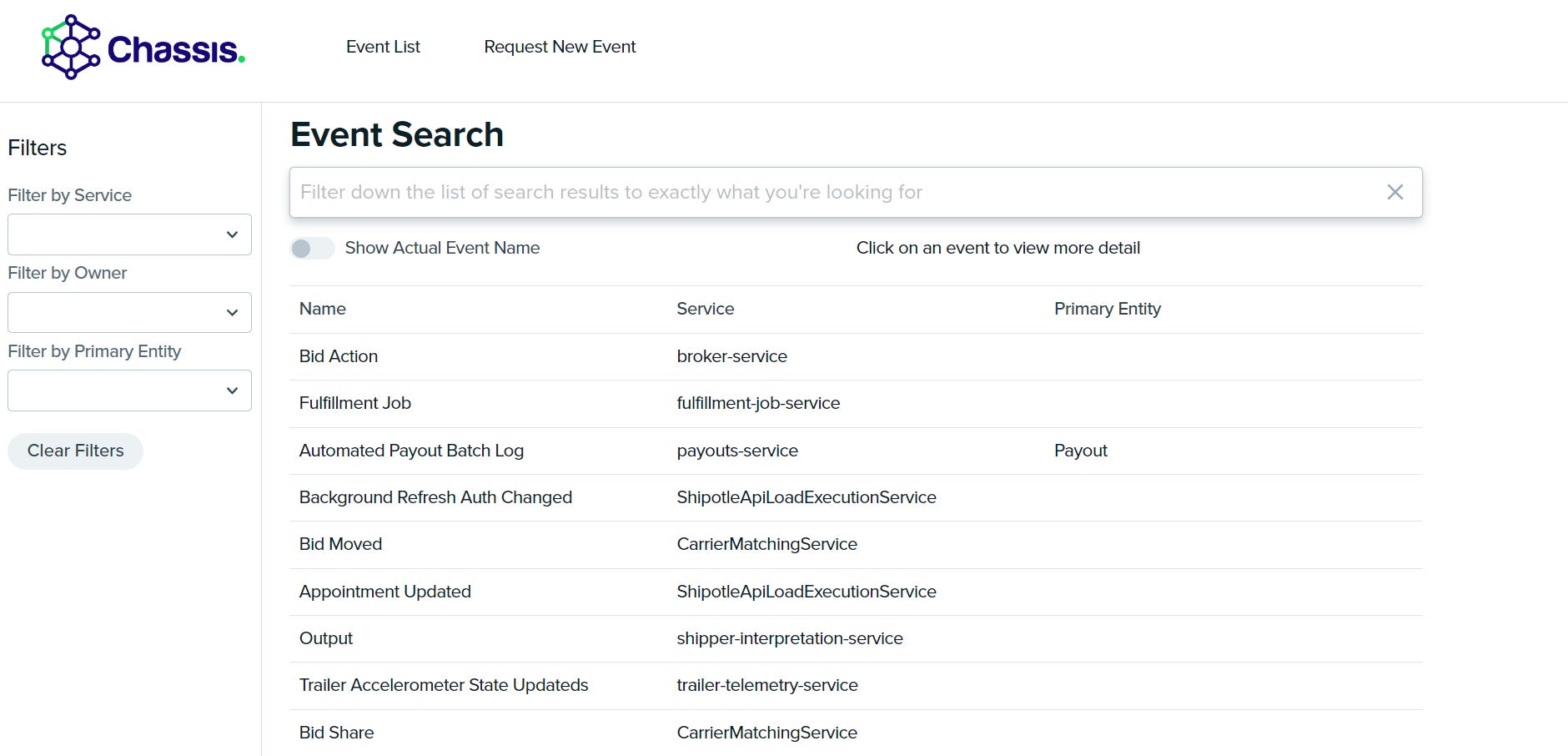
The complexity of our business needs are compounded by the number of stakeholders who must frequently manipulate data, resulting in teams operating in fast-moving silos. Without clear methodologies for collaborating up and down our data stack is it any wonder why the Data Warehouse rapidly devolves into a Swamp?
The products of the Modern Data Stack were primarily developed in highly mature data ecosystems to solve very specific infra issues. The tools were not fundamentally designed to operate in a workflow. This is not necessarily a bad thing (In fact, I think most tools in the MDS are excellent) but it creates a mentality rooted in ‘what’s next?’ instead of ‘Are our fundamentals in place?’
Mohammed Aaser, CDO at Domo gives a take I agree with:
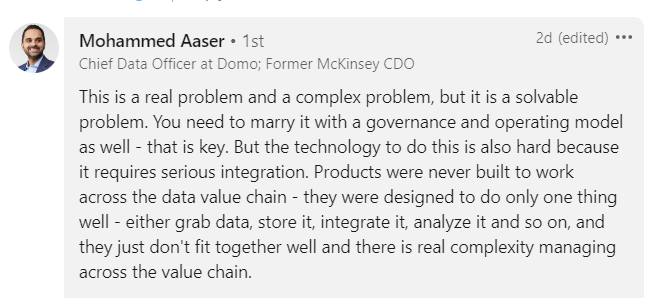
What Must Change
The largest problems with Modern Data Stack aren’t technical - they are collaborative. Automation or AI on top of a broken Data Warehouse is not scalable or useful if the underlying data is low quality, changes frequently, has little ownership, and lacks a system for ongoing maintenance.
The collaboration problem can be defined by a few key open issues:
No ‘True’ Data Warehouse
Philosophically, the reason data modeling is useful is that it is an abstraction that bridges the gap between our data and the real world. Semantic concepts - entities, their behavior, the relationships between them, and their properties- modeled effectively in a true Data Warehouse provide an environment for data consumers to explore the edges and nodes in this semantic graph and build agreed-upon derived concepts/metrics. The Warehouse forms the foundation for all analytics. Without it, tech debt will continue to spiral out of control.
Lack of a Collaborative, Iterative, Modeling Environment
Modeling is a critical step in the development of any legitimate Data Warehouse. However, the historical challenges with modeling (slow, high governance, not iterative) must be resolved. Data Modeling 2.0 must be reinvented for the Modern Data Stack in a way that is collaborative and business-centric.
Engineering Separation
Today, Software Engineers are disconnected from the analytics workflow. Despite producing the majority of data used in critical business reports, experiments, and models, SWEs have virtually no idea how their data is being consumed. This makes the Data Warehouse a minefield of poor-quality data. Engineering must be brought deeper into the data generation lifecycle and given the responsibility that any producer should have in a software-driven system: maintenance and quality ownership.

Non-Existent Product Thinking
Applying product thinking to data is rare in today’s data environment. ELT systems make it easy to throw data over the fence to consumers who stitch the world together post-hoc. Data Product thinking means being deliberate with the data that is needed to solve business cases. It requires stakeholders to ask great questions and make reasonable requests:
What are the business questions we are trying to answer?
What would be the business impact of answering these questions?
What real-world behaviors do we need to record to help answer those questions?
What is the level of trust we need to have in the data?
How timely do we need the data to be?
Juan Sequeda, Principal Scientist with Data.World wrote an excellent article on the ‘ABCs of Data Products’ that I strongly suggest checking out. A simple mindset shift towards data product thinking would work wonders for most organizations.
What about Data Frameworks?
Whenever conversations around Data Usability or Ownership are brought up, inevitably questions about Data Mesh, Data Vault, and Data Fabric follow. To be frank, I am neutral on every framework. In my opinion, which framework is leveraged is relatively inconsequential and depends on business needs at the time. A centralized system can work, as can a federated system. The bigger challenge is still collaboration and design.
How do you facilitate the prioritization of this framework?
How do you reduce the overhead of implementation?
How does the framework evolve over time?
How do you ensure the framework is not a one-way door and can be altered?
How do data, product, business, and software teams work together as a cohesive unit in this framework?
What happens if the data you need exists across teams?
How do you facilitate strong data modeling?
In my mind, these are the biggest questions to be answered. They represent the human side of data projects, one which has been largely ignored.
In closing, I don’t think that the industry needs yet another data technology from Big Tech. What we need is a return to the tried and true practices that formed the beating heart of all data warehousing and analytics. Those practices are the result of strong collaboration and effective design. By adopting data design at scale, we can turn the data industry from something that businesses struggle to derive value from, to one that generates value almost by default. Despite my seemingly negative outlook on the Modern Data Stack, I am incredibly optimistic about our future. I think the world of better design is coming, and I can’t wait to see what innovations in collaboration help take us there.
If you want even more content be sure to follow me on LinkedIn for thrice weekly posts, and if you liked my article, please consider subscribing. I post once a week, every week. Thank you so much for reading and let’s talk again soon.
With data we have an issue comparable to that of logistics, new bottlenecks pop up as soon as a 'solution' is chosen. In each new situation new solutions are needed to mittigate the bottlenecks, which the technological solution approach can hardly be.