
How Scale Kills Data Teams
And Why the Modern Data Stack Isn't Enough To Save Them

Note from Chad: 👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and I write about data products, data contracts, data modeling, and the future of data engineering and data architecture. Today we’re tackling a big problem (literally): Scale. This article is a long one, so strap in. As always, I‘d love a follow and share if you find it valuable.
A few months ago I was talking to the Head of Data at a well-known Fintech. At some point, the conversation moved to how many modern businesses are taking the wrong approach to AI. The Head of Data exasperatedly threw up their hands: “The company wants me to build a sophisticated fraud detection model, but they aren’t willing to give me the resources to train it on good data. I’m not sure what they expect from all this.”
The sentiment isn’t uncommon. From eCommerce companies to large-scale manufacturers there is a hunger for ML/AI that is unlike anything I have observed over the last ten years. Innovative data leaders with long tenures at Google and Amazon are brought in with lofty promises to champion a transition to machine intelligence at scale, only to be met with roadblocks, resource constraints, and data quality issues.
Everything starts smoothly. A freshly hired executive with PowerPoint and roadmaps in hand gives a rousing presentation to an executive team that spouts about being ‘data driven’ before allocating funding for a small group of data scientists and ML engineers.
After minimal onboarding, the scientists whip up their favorite notebook, pull data from a random S3 bucket (“I think that looks like the data we need?”), and begin to run massive linear regressions. The business leans into tools like AWS, Snowflake, Sagemaker, K8s, dbt, and Airflow. They build their first training set and before long a prototype is in production. People cheer.
But then…things start to go downhill. The model fails for no apparent reason. When the data science team investigates they discover a wall of technical debt written 8 years ago that no one understands. After pinging the #data Slack channel they receive very few meaningful answers and eventually write a ticket to the data engineering team’s JIRA backlog.
What follows is weeks or months of back and forth, confusion, bickering over ownership, and an eventual breakdown in quality that leaves everyone exasperated and moving at a snail’s pace.
Why does this happen? Well…because of scale. But what exactly does that mean?
Scale Means Organizational Complexity
When most software engineering teams think of scale they imagine a surprising number of API calls or millions of records written to a database in a concerning period of time. For 99% of data developers, we don’t have that problem.
Scale for Data Teams is an issue of organizational complexity.
In most early-stage companies the first set of data pipelines was created by a single data engineer. Overloaded with work, data engineers do their best to string together one pipeline after another with minimal testing, documentation, or data modeling.
What results is an infrastructure that barely gets the job done. When Product and Marketing teams are eventually pushed to provide quantifiable business impact by executives, they turn to the data engineer. Dozens of dashboards are spun up in a short period of time that will eventually form a graveyard of wasted pipeline runs for metrics that no one cares about anymore. Each of these asks has an opportunity cost for time and a literal cost of cloud spend.

As the business grows in revenue and venture capital funding, the software engineering discipline doubles and triples in size. Following AGILE, teams deploy iterative changes ranging from small bug improvements to features that significantly alter the customer experience. The data engineer can only keep up temporarily. Eventually, the deployment velocity is too much to manage, and expectations of what the data means and its underlying implementation fall out of sync.
Software engineers make reasonable and locally optimal decisions for the services they maintain. Perhaps they drop a column from their production database because it’s no longer useful, split one column into three, or alter the underlying logic of how discounts are applied to an order.
While that’s fine and good for their own applications, the downstream consumers of the data are affected in various ways: Schema changes cause pipelines to break altogether and business logic changes cause dashboards to show the wrong data and reduce trust. Data producers remain unaware of this problem while data scientists only recognize something is wrong when their most important data assets start to behave unexpectedly.
Once a data issue is detected, data consumers may investigate or review any PRs for problematic repos they may have missed. This is time-consuming and challenging to do, ultimately, landing most data issues as a ticket on a central data engineering team’s JIRA board. Hounded by the business to deliver 🌟value🌟 data scientists write filters on top of an already complex SQL query in order to hold themselves over in the meantime.
Data Engineers spend days to weeks attempting to track down what caused the problem. When they finally do, it’s (as expected) an upstream issue. The data producer has already moved on to another project, and it’s up to DEs to create backfilling jobs that recognize the new state of the world while patching up the old as best they can. Data consumers quickly lose trust in the complex SQL queries stitched together by their fellow data scientists. Who can be bothered to parse through hundreds of lines filters and CASE WHEN statements with a product manager breathing down your neck about deliverables.
The data consumer decides it would be easier to derive the 'truth’ directly from the producer instead. They have a Zoom meeting with the application developer and pull together a new dashboard with the same meaning as the old dashboard, leveraging SQL only the table owner can understand. When the next upstream breaking change occurs, there are two downstream failures instead of one and the process begins anew.
In such a vicious cycle revolving repeatedly over the course of months and years, data quality starts to spiral out of control at an exponential rate. The organizational complexity of managing changes to many different data assets all at once creates hurdles for each stakeholder. Inevitably, pointing the finger at the other side is about as far as anyone gets toward actually solving the problem. At this point, it’s common for data leadership to try something drastic. Data teams might:
Buy a new data-quality tool
Switch to a different organizational paradigm
Lobby for a large-scale refactor (and usually fail)
Create data governance councils, committees, and other groups
Cry
While well-intentioned, each of these solutions is addressing a symptom and not the root cause. That is not to say shiny platforms and refactors have no place in any data team's toolbox. They do! However, too often they are treated as band-aids for a gunshot wound. When your data foundations are riddled with tech debt to their core, the only way out is to resolve the problem at its source.
The Death of the Data Warehouse
In the 1980s, Bill Inmon coined the term Data Warehouse. The Warehouse referred to an integration layer where data teams could unite data from various sources to form an accurate reflection of the real world through code. This made the Data Warehouse an ideal source of truth. Creating such a valuable, and comprehensive asset required a data architect sitting at the choke point between producers and consumers. Effectively, the ‘T’ in ETL was a human being who understood the data and its applications extremely well and was paid good money to make high-quality data accessible to the rest of the business through solid architectural design and strong data modeling.
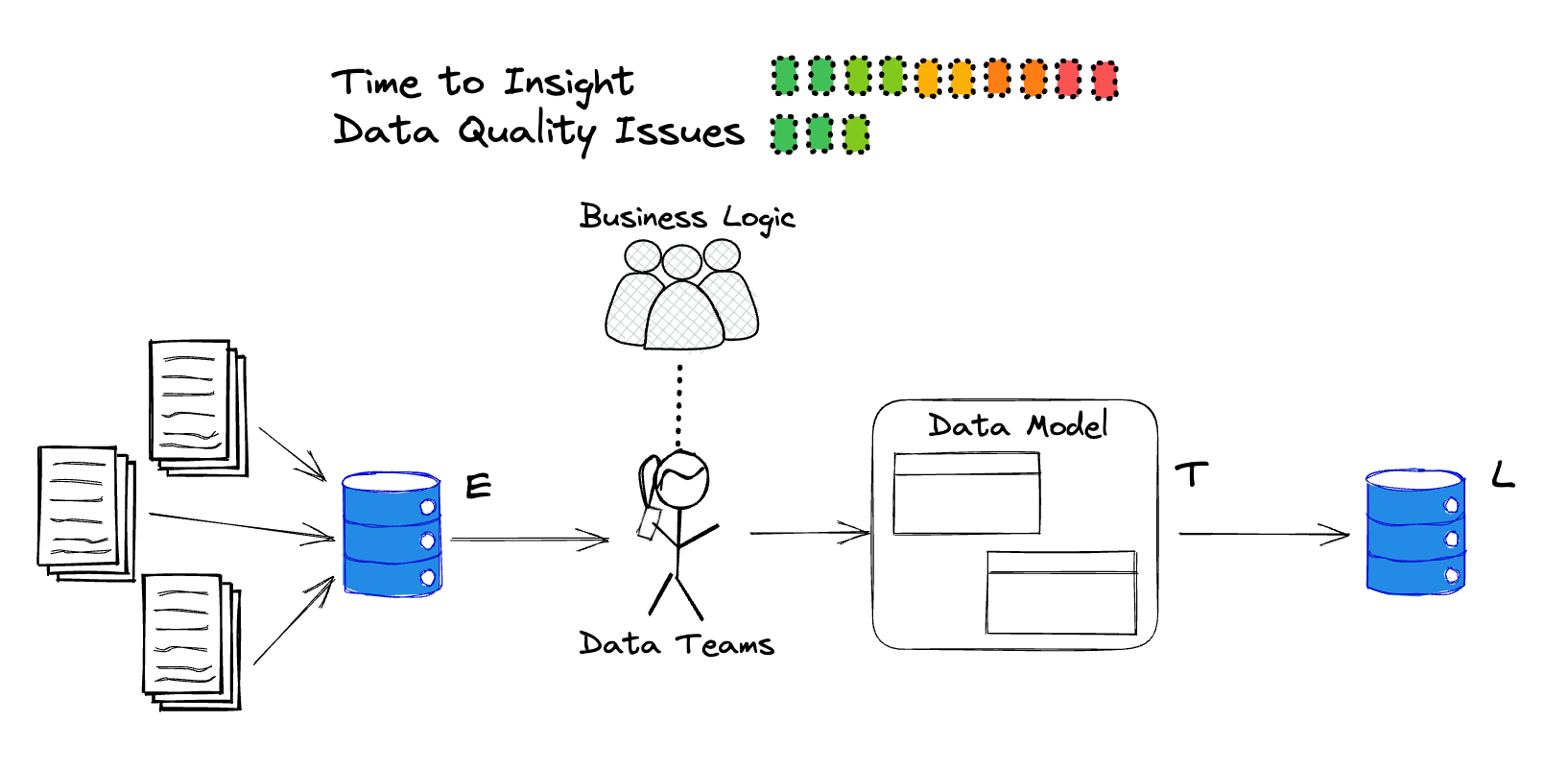
Thanks to the rise of AGILE (there’s that word again) data architects fell out of vogue. As companies began to shift towards a faster, more iterative, micro-service-driven development strategy it was cheaper and easier to dump all the data in one place and get the data engineering team to sort through the mess later. We call this a data lake.
As the popularity of data lakes and by extension the lakehouse grew, the role of data developers began to change. Data Engineers emerged as pipeline builders responsible for moving data from production to a landing zone, parsing the raw data into more discoverable data assets, and managing light transformations which could be made accessible to the rest of the business.
This was an ideal model for startups. When a company is small data developers can afford to be in the ‘room where it happens.’ If changes are made upstream by application engineers the data team ensures their needs are considered as part of the product spec. This prevents pipelines from breaking and allows downstream teams to focus on business logic (what they know best).
Moving fast is the name of the game. As long as the data is directionally correct it is unlikely that perfect accuracy would result in a different decision being made by marketing or product teams. “So what if your app usage numbers are off by 20%?” they might say. “If we have a general idea of what’s working and what’s not do we really need the additional cost required to maintain 100% accuracy? After all, we have features to build, money to burn, and layoffs to prepare for.”
As companies snapped to this new reality, toolchains emerged to enable data developers to be productive in a bottleneck-free world. “Move fast and break things” defined a generation of tools that we have come to know as The Modern Data Stack. ETL became ELT. Tools like Fivetran allowed data engineers to connect to any source system and move data in minutes (“load first, ask questions later). dbt let anyone build data models using SQL through a CLI. (“transform first, ask questions later). BI tools were tacked on top of views that allowed analysts to rapidly construct visualizations and answer one-off questions. (“Create dashboards first, ask questions later”).
This shift in priorities, architecture, and job function effectively killed the Data Warehouse. And with its death came an end to the source of truth and a 180-degree turn toward democratization. However, with democratization comes chaos. A lack of managed truth means that anything can change at any time, and when those changes don’t map back to our expectations, bad things happen.
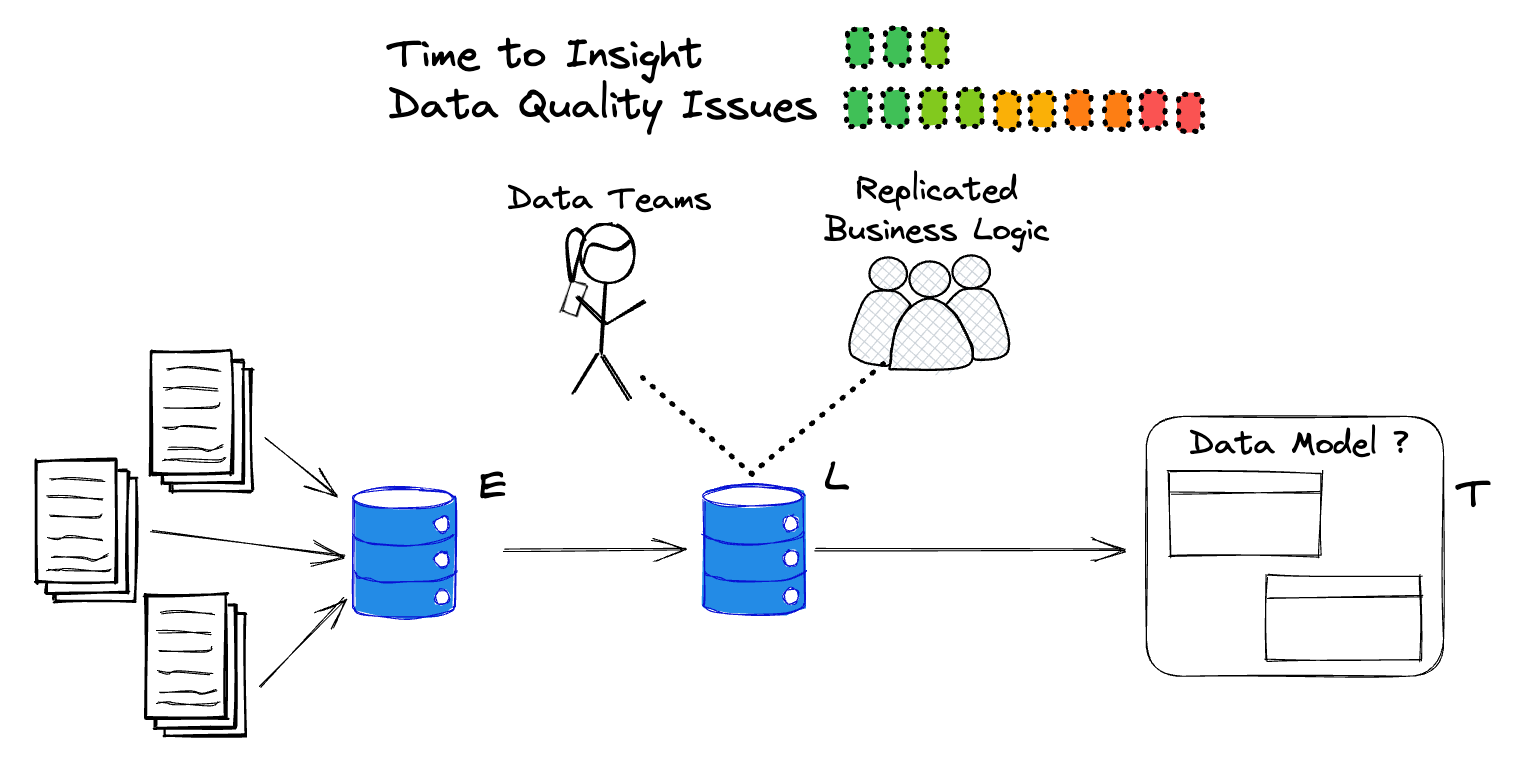
A Post-Truth World
On paper, more freedom and flexibility is always a good thing…but is it really that way in practice?
Industries where improper product use could result in consumer harm must have a higher standard of regulation and compliance. The greater amount of trust that is needed in the product to serve its function, the greater governance is required to ensure that consumers don’t hurt themselves by pushing their own limits. This theme rings true in data management.
A data scientist who uses the item_pricing table makes an assumption the data they are leveraging is up-to-date, semantically valid, and accurate. They build reports based on these assumptions of trust, which are translated into decisions by the business. Teams create marketing campaigns, invest in new products, and expand headcount all based on their trust in the data.
In a post-data warehouse world, the assumption is typically only that: An assumption. There is no evidence that the item_pricing table contains up-to-date information. There is no business expert who controls the floodgates to production ensuring data consumers are making the right choices, and there is rarely documentation to even explain how the data should be accessed or what a single row in a table represents. An explosion of unreliable data emerges as a result.
What made sense for the start-up no longer works at scale. When applications require trust, like AI/ML pipelines, data products, or financial reporting, the flexibility of the Modern Data Stack and its democratization suddenly becomes a massive liability.
To see the impact of ‘moving quickly and breaking things’ at scale we can turn to embattled micromobility company Bird. Late in 2022, Bird announced they had overstated company revenue by two years from recognizing unpaid customer rides. According to TechCrunch:
Bird said it had recorded revenue on certain trips even when customers lacked sufficient “preloaded ‘wallet’ balances.” The company said it should have reported the unpaid balances on its financial statements as deferred revenue.
An internal investigation found that the company’s “disclosure controls and procedures are not effective at a reasonable assurance level.”
Yikes.
One of the most telling statistics on the topic comes from a survey of finance professionals by Blackline. The survey found that while over half (54%) of total respondents still claim to completely trust the accuracy of their own financial data in general, there is a significant discrepancy between the views of the C-suite and that of finance individual contributors. While 71% of C-suite respondents claimed to completely trust the accuracy of their financial data, only 38% of finance ICs said the same.
Data Catalogs Are Not Enough
Data catalogs attempt to solve the issue of trust through discoverability. The assumption is that if data is much easier to find it will lead to greater consolidation and reusability. While understanding where your data is and how it is being used is essential, catalogs are not the right tool to overcome the problems mentioned above.
For one, catalogs are reactive. They only respond to the business after it changes. Secondly, because modern catalogs are derived from metadata on top of the cloud analytical database there is a limit to their purview. What happens if a Salesforce administrator decides to delete an important column or an application developer alters the underlying business logic of a PostgreSQL table? What happens if an application developer refactors their database which breaks 100% of downstream consumers? What happens if a new feature is launched that fundamentally changes our understanding of a certain column from X to Y? The data quality issue has already happened - now we’re just dealing with the fallout. In short, it’s Garbage In, Garbage Out on steroids.
Data Catalogs are a record of what has already happened, but they are not a framework for ensuring that the right information is communicated to the right person when things change. To put it simply, because no one is accountable for managing the state of the data at all times, then looking at the state of your data at any point in time contains no information that verifies the assumptions which have been made about it. Owners are defined in name only, not function. It is not the responsibility of the dataset owner to manage the expectations of data consumers because they were never asked to do so!

So what does all this mean? Unfortunately, the rise of the Modern Data Stack demonstrates that we are living in a post-truth world, quite literally. By the time data teams learn that something has changed, it’s already too late. We are constantly in the position of playing catch-up, always reacting to the world around us after the damage has already occurred, and in some cases never reacting at all. In my opinion, there is no bigger challenge to solve in data than this. Reverting back to the old methods is not possible. The world has already moved forward.
Summary
So let’s review:
The initial data infrastructure wasn’t designed for organizational scale
Data producers don’t understand how data is being used
Data producers make locally optimal changes that break teams downstream
Data consumers are reactive and layer filters on top of nasty SQL queries
Data engineers are stuck in the middle, constantly responding to issues they didn’t cause
The data in the lake grows exponentially with no controls or trust
Teams move rapidly to build new models, duplicating existing work
The Data Warehouse ceases to exist
Data Engineering teams maintain a swamp of tech debt
Data falls out of trust
No one is happy
Sounds like a really nasty, hairy, problem to solve. You might expect it will take a complete overhaul of the system and a total restructuring of how we think about data to fix it, right? Maybe it means hiring for new roles like a Data Product Manager or orienting the business towards data domains. Maybe it means imposing strict limitations on data consumers and producers or having weekly Data OpEx meetings reign in usage. It may mean getting rid of all the great tools that helped us move fast for some slower, heavier systems. It may even mean abandoning democratization entirely.
I disagree with all of these approaches. Moving fast is good. Data teams must create incentives for producers to care about how data is being used. Data governance must be iterative and applied at an appropriate level when and where it’s needed. The solution is surprisingly, painfully simple. Better data communication.
While there are many ways to tackle data communication, this is actually the problem I am attempting to fix at Gable. You can check out the larger write-up on that, and how we’re solving the problem below:
Thank you so much for taking the time to read this mammoth write-up and please subscribe to the newsletter if you enjoyed it! Also, every share helps me grow (and gives me the motivation to keep writing pieces like this) so that would be incredibly appreciated as well. Follow me on LinkedIn and now Twitter for more posts on data engineering, data ownership, and data quality.
Good luck!
-Chad
Ok this seriously triggered me! And I see pretty much all of this where I work! You can’t get two numbers to reconcile? Just create another query. Or a table. And so on...
Really enjoyed this article, recognize quite a bit. Looking forward to part 2 - the solutions ;)