
Tackling Data's Biggest Culture Problem
Introducing Gable.ai

Note from Chad: 👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and I write about data products and data contracts. As of today, I am officially taking on the title of Founder. This post explains the why, the how, and the what of my new venture. As always, thank you for the support and please share if you find it useful.
The Problem
After a career working with large-scale datasets at Microsoft, Subway, SEPHORA, and Oracle I went on to lead the Data Platform team at a company called Convoy. Convoy was my first startup. From a data perspective they were exactly as you might imagine:
Cloud Native Tooling: S3, Snowflake, Fivetran, dbt, Airflow
Scrappy pipeline development
Heavy reliance on Machine Learning and Data Applications
More of a ‘build first, deal with consequences later’ attitude
I was impressed by the quality of infrastructure, the speed data moved through the pipeline, and the efficiency of storage costs. However, there was a problem. Everyone seemed to distrust the data.
There was virtually no reusability of existing queries, an exponentially increasing number of dashboards and data models, no governance, and low data quality. These issues were beginning to have tangible impacts on the company’s ability to scale data to high-value operational use cases.
I tried everything I could think of to solve the problem:
Implemented a data catalog
Implemented a semantic/metrics layer
Invested heavily into better testing and monitoring
Created a data governance committee
Create a dataOps group
Invested in more training for improved data literacy
and more…
And yet the team remained unhappy. Data engineers were constantly getting paged at all hours of the day and night due to broken pipelines or changing business logic. We spent more time trying to debug the root cause of data quality issues than we did innovating. Our stakeholders were constantly asking for a source of truth dataset, but my team only maintained the infrastructure - we had no clue about the business logic developed in analytical siloes.
At my wit’s end, myself and Adrian Kreuziger (Data Platform’s Principal Engineer and author of An Engineer’s Guide to Data Contracts) set dozens of meetings with companies like Twitter, Spotify, Netflix, Discord, Opendoor, and Wayfair to understand how their data teams had resolved this problem. Surely, there was something uniquely wrong at Convoy. A simple fix was imminent.
What we heard back was startling: Every team felt the same pain, but no one had a satisfying answer to a solution. Something was deeply wrong in data. What was the point of all this infrastructure, process, and resourcing if ultimately the data was barely being used, was constantly broken, and couldn’t be trusted?

So, we started our investigation from scratch leveraging first principles. What were the root causes of the lack of trust? Why was it so difficult to resolve them?
Here is the answer I found after months of interviewing data scientists, data engineers, software engineers, and business users from companies ranging from tech startups to international banks to legacy on-prem logistics companies:
Modern software teams often treat data as a by-product of their application
Data teams take dependencies on upstream sources without a clear contract
When software teams change their data, they have no visibility into where the data is being used, who is using it, or why it is important
By the time a failure has been detected downstream, it’s already too late. Garbage In, Garbage Out.
Data Consumers layer filters and other hacks on top of the data so that it continues to work as expected
These hacks create data debt. As data debt grows, analytical environments become more opaque and confusing
Duplication emerges as data consumers would rather rebuild queries than use existing files they don’t understand
There is no longer a source of truth and teams struggle to trust the data.
With this in mind, it began to make sense why the previous solutions I had envisioned didn’t work. When I tried to tackle the problem with technology like Monitoring and Cataloging (tools that consumed metadata from our analytical environments) the problems were detected far too late. They were reactive, not preventative.
When I tried to tackle the problem with processes like governance committees and ops reviews, these frameworks were effective but too slow and unscalable. The engineering team continued to ship rapidly whether our small governance team was there to enforce standards or not.
The solution to this problem needed to be fast, iterative, scalable, and most importantly: focused on the connections between people.

Enter the data contract.
The data contract was my solution to bring data producers and data consumers together around the management and enforcement of constraints on upstream data assets for the benefit of downstream data products.
The data contract is similar to an API. It is an interface for describing the requirements on a data set, created collaboratively and implemented as code. The contract includes both the API specification and the mechanism of enforcement. Most commonly, the spec includes the schema of the data, business logic, and its SLA.
Enforcement of the contract is key. Data contracts must be enforced in CI/CD or else they will not be preventative (and therefore, not solving the core problem). Enforcement can take a variety of different forms.
Breaking the build entirely
Informing producers and consumers a contract violation is about to occur
Preventing deployment until consumers have given their sign-off
And so on, and so forth…

During my time at Convoy, we implemented dozens of data contracts and the impact was profound. My internal metric for measuring the success of this initiative was ‘the number of conversations created between data and dev teams.’ I was happy to report that the number spiked, and data awareness/literacy across the organization improved virtually overnight, though we were still a long way off from the promised land.
Around this point in time, my writing on data contracts began to take off and I had some extremely compelling ($$$) reasons to leave Convoy. I began working with other teams on the implementation of data contracts at scale.
During my work with these forward-thinking folks, it became clear that the primary value of data contracts was not only as a mechanism for preventing breaking changes but as an incredible tool for bridging the communication gap between data producers and data consumers. The number one feedback I heard from software engineers was the following:
“I had no idea anyone was using my data like this.”
Visibility created a dramatic shift in the way software engineers worked with data teams. After becoming more familiar with the downstream consequences of a breaking change, and the number of dependencies the business had taken on their source data, the level of interest developers had in improving the quality of their data assets skyrocketed.
Conway's Law is an adage that states organizational design systems mirror their own communication structure. It is named after the computer programmer Melvin Conway, who introduced the idea in 1967 and was hilariously visualized by the excellent Manu Cornet below.
If an organization experiences constant data quality problems, it implies that there is likely a faulty relationship between the producers of the data and the consumers of data stemming from a lack of visibility.
This complete lack of visibility results in data quality issues, in the same way a lack of code visibility between engineers results in code quality! If changes are being made across an organization with no context on how they impact others, it is natural that things will break over time.
In software engineering, this problem is addressed through systems that allow for more iterative local human-in-the-loop review. GitHub and GitLab are two common examples. Software engineers can directly subscribe to the repos they care about, ensuring that any changes are at minimum communicated to the teams who care the most.
In data this problem is far more difficult to solve comprehensively for several reasons:
1. Most data consumers don't care about GitHub repos
2. With many complex transformations, it is hard to understand where data is flowing from
3. Not every change to a service is a breaking change that affects the data
4. Not every breaking change is impacting an important data product
5. Code review happens within teams, data review should happen between teams

This is the penultimate value proposition of data contracts. They are not simply a mechanism for improving data quality, but for facilitating culture change by providing visibility into how data is being used, connecting data producers and consumers at the right time (code review), and creating a vehicle for data change management across the organization.
The Solution
Gable.ai is a data communication, collaboration, and change management platform. In essence, we are doing for data what GitHub did for code, specifically designed for data’s unique workflows and challenges.
The foundation for Gable is the data contract. Data contracts can be defined within the platform or using an OpenAPI-like specification and manually added to relevant repositories. Anyone can suggest data contracts: data platform teams, data engineers, or analytics engineers.

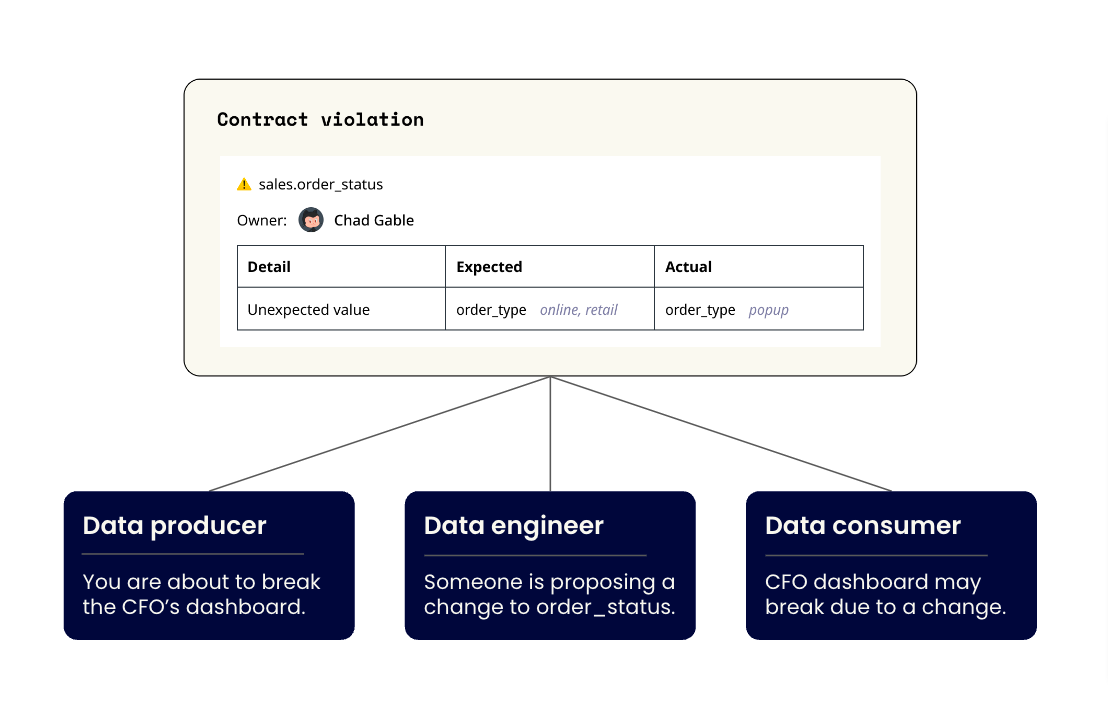
Once teams have published contracts to protect important data assets, data teams can leverage checks in CI/CD to prevent changes in product repositories that would violate a data asset's contract.
Depending on the tier/importance of a data contract and the severity of a violation, Gable can take a set of predefined actions that range from failing the build, to commenting on the offending pull request, to tagging consumers that have subscribed to contract violations.

The goal of all of this is to create a technical foundation that facilitates better insight into how data is managed and evolves iteratively as an organization grows. By connecting people at the right place and time, data engineers no longer have to respond reactively when something breaks. Data producers can understand who has taken dependencies on their data and why. Data consumers can prepare for migrations or provide feedback on planned changes.
Is Gable going to be the magic tool that solves all data quality issues? No, in the same way, GitHub can’t solve all code quality issues. However, like GitHub, we can do an amazing job at bringing people together to have conversations about data and its importance to the business through a common language while providing a system of record for tracking how the data changes, who changed it, when did it change, and why.

Gable is the sum total of my beliefs in the data space. I hope it’s something that you find value in, once it’s ready. We’re still far away from officially opening up the product, but if you want to be kept up to date on our progress and join the private beta in a few months, you can sign up on the website site below. I hope you will!
This Substack is still going to be used as an outlet for my thoughts on data, whether they are associated with the new company or not. Data Quality Camp (our community) will still be vendor-neutral, and I’ll follow the same rules as everyone else. Our book on data contracts will be released next year. That is to say, I’ll be doing more of the same content production I always have- but also trying to tackle a huge, huge problem in the data space in parallel. Wish me luck.
A few acknowledgments
Gable is a direct result of 1000s of hours of conversations with all of you. Your thoughts, feedback, and perspectives on data made this all possible. Thank you.
I also want to thank my two other founders and early team: Adrian Kreuziger and Daniel Dicker, both of whom I’ve known for years and have slogged through this problem together when there wasn’t a clear answer in sight.
Next, I’d like to thank our amazing investors, people who believed in us at the start of a recession when data investments weren’t sexy anymore. Apoorva Pandhi (Zetta VP), Scott Sage (Crane VC), Tim Chen, Allison Pickens, Tristan Handy, Barr Moses, and many more.
Finally, I’d like to thank my family: My mom, dad, and sisters - for putting up with me working obsessively on a weird data project, and my soon-to-be amazing wife, Laila Hofilena, for marrying me despite the fact I’m officially living the founder lifestyle. I don’t deserve her.

Thank you for all the support so far. On to the next part of the journey.
-Chad
Congratulations Chad. Funny that I visited your publication earlier to read your post on data modeling and was wondering why you've been so quiet (although I had an idea).
Also funny that you mentioned that organisations need "good data" whereas most have bad data -- this is the foundation for a new series I'm working on, happy to share an early draft if you're interested.
Good luck with Gable! 🥁🥁
This is pretty exciting!