
An Industry Shift: Moving From Collecting to Automating Metadata
An Introduction to Apache Iceberg and How It Can Work With Data Contracts


Note from Chad: 👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and I write about data products, data contracts, data modeling, and the future of data engineering and data architecture. Mark is taking over for this article, but I wanted to quickly share that I worked out a deal with O’Reilly so that people can download our upcoming book for free on our website. Follow the below link, and you will get access to the early-release chapters. People who sign up will also receive follow-up emails with updated PDFs with new chapters until the book's full release.

A few months ago, I was invited to present at the Chill Data Summit on how data contracts can work with Apache Iceberg, a rising-in-popularity table format for data lakes. Thus began my deep dive into learning about Apache Iceberg, specifically reading the book Apache Iceberg: The Definitive Guide. Similar to our book on data contracts, their first chapter describes the pains experienced by data lakes and the overall direction of the data industry. It became clear to me that data contracts and Apache Iceberg were solving similar problems but from different ends of the data lifecycle. Furthermore, while it’s still early, I see Apache Iceberg's merits and the table format potentially becoming an important architecture component for companies that utilize data lakes.
By the end of this article, I aim to provide the following:
How Apache Iceberg and data contracts are fueling the shift from collecting to automating metadata.
An introduction to Apache Iceberg and its architecture.
How Apache Iceberg could potentially work with data contracts.
An Industry Shift: Moving From Collecting to Automating Metadata

A common question I get about data contracts is, “How does this differentiate from data catalogs?” Data catalogs are a great starting point, but just knowing about your data is no longer enough. Yet, taking action on this knowledge is a monumental effort.
As an analogy, we previously had to navigate our world using maps before smartphone apps, where we had a dense amount of information on locations, the roads that connected them, and key landmarks. While navigating your familiar local area was trivial, expanding from there required substantial research and tracing various roads—not too dissimilar to navigating unfamiliar databases and their lineage. With the advent of apps such as Google Maps, this research and navigation has been automated. Furthermore, automation even informs us of real-time changes, such as traffic conditions or updated directions after taking a wrong turn.
I argue that the data industry is moving towards its “Google Maps” moment, where we are moving from just collecting and reviewing metadata to now automating actions based on the changing metadata within our data systems. Specifically, abstracting away the operationalization of metadata via automation enables companies to take action at scale. I see the emergence of data contracts and Apache Iceberg as examples of this shift towards automating metadata-based actions. In the next sections, we will dive into what this looks like.
Apache Iceberg and Grocery Shopping

Before discussing the details of Apache Iceberg's architecture, it's best to understand what it's doing at a high level. Thus, the following analogy provides a starting point:
You are a chef (analyst) who needs to go shopping for ingredients (data) for a private dinner you are preparing (report) for a client. You know what meal you are making, and you already have a list of instructions and ingredients (SQL query + data).
So you go to the grocery store (data lake), but your client lives on the other side of town, and thus, you have never been to this store. So, you spend tremendous time searching across the aisles (database scanning) for your ingredients. You eventually get everything, but it was a cumbersome process.
The dinner went great, and your client wants to hire you again for their massive wedding! Knowing that this substantially scales up your required shopping efforts, you must be more efficient. Therefore, you choose a grocery store (data lake) with a shopping app (Apache Iceberg).
Like last time, you are at a grocery store where you have no idea where things are, but since you have their shopping app (Apache Iceberg), you don't have to worry about aimlessly scanning the aisles looking for your ingredients (data files). Instead, the app has a catalog of every item in the store (Iceberg Catalog) and the aisles (metadata file) where ingredients are located (e.g., frozen, deli, etc.).
Furthermore, because the app keeps a log of where ingredients are, it can also inform you when items have moved to different aisles (snapshots/time travel/schema evolution). While this is a huge upgrade from the last time you went shopping, the app takes it even further! You can provide all your ingredients, and the app will determine an optimal path (manifest file) to navigate the store and quickly shop for your ingredients.
Looking for ingredients for ingredients at the grocery store has never been easier!
Apache Iceberg Architecture Breakdown
Now, let's move away from the shopping analogy and speak directly about Apache Iceberg:
Apache Iceberg is a table format that's essentially an abstraction of metadata so different tools can quickly navigate the files within a data lake.
Without Apache Iceberg, you typically have to scan across multiple files to query your data.
To speed this up, Apache Iceberg leverages metadata to optimize its execution plan.
Furthermore, Apache Iceberg supports ACID compliance. This is a HUGE DEAL as the main reason people used relational databases was for ACID compliance, and typically, the tradeoff of data lakes was flexibility at the cost of ACID. Specifically, this is great for data quality.
But how does that happen? Let's break it down.
Apache Iceberg consists of three layers:
The Iceberg Catalog
The Metadata Layer
metadata files
manifest lists
manifest files
The Data Layer
data files
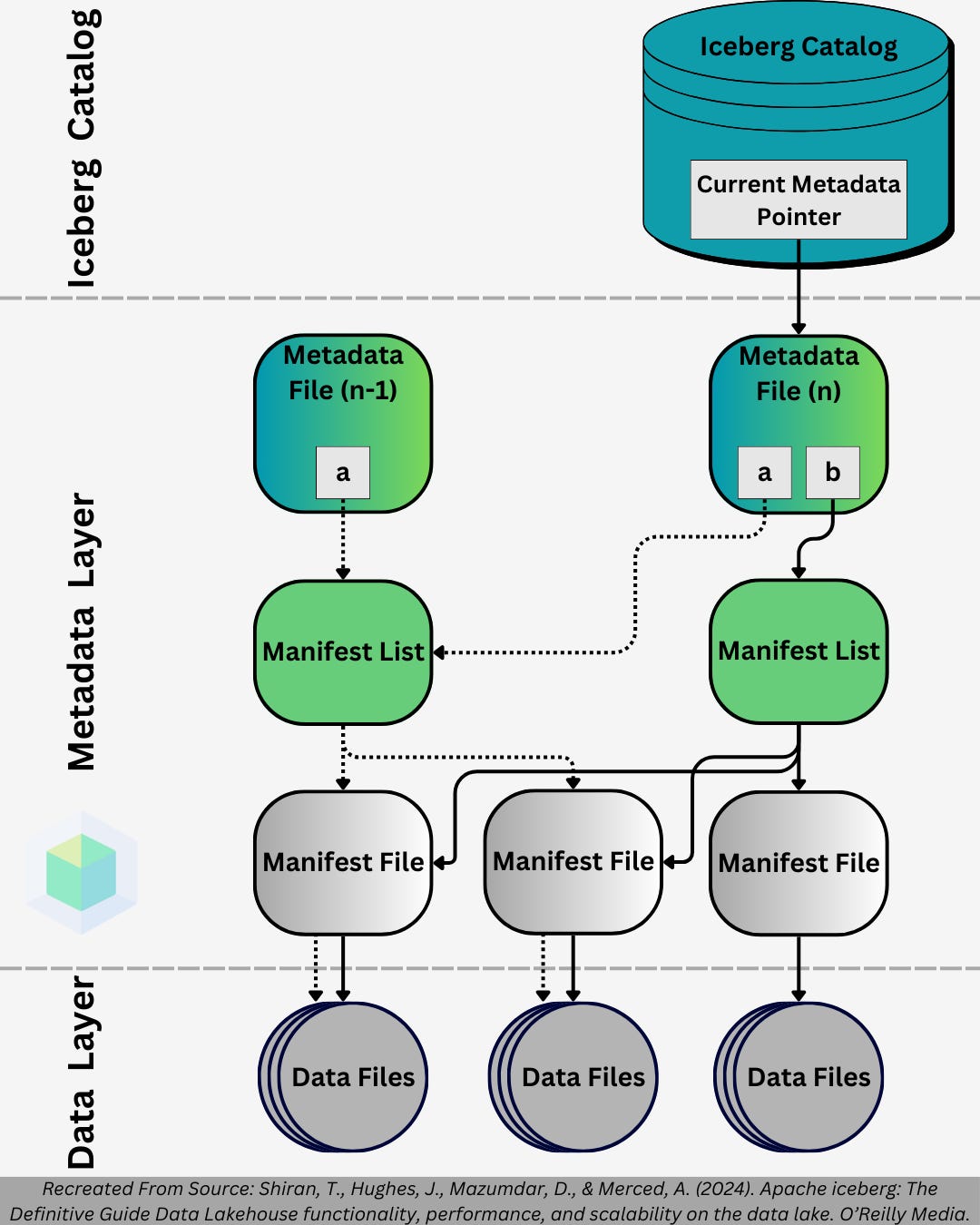
The Iceberg Catalog
This is essentially a data catalog, but one key point to highlight is that “...it must support atomic operations for updating the current metadata pointer... This is what allows transactions on Iceberg tables to be atomic and provide correctness guarantees." We will go into this a little later why this is so important.
Note: The Iceberg Catalog is an important component but outside the scope of this article. I suggest reading the following to learn more:
The Metadata Layer - Metadata Files
These files contain the metadata that compose the Iceberg Catalog. Specifically, metadata files serve as a store of "snapshots" of the files that form tables within a data lake. The following are stored in these metadata files:
table id
location path of the files
schema of the files
partitions
Note: Apache Iceberg automatically handles partitions—this is huge for data engineers, as this is normally handled manually but outside the scope of this writing.
There are also some important key features here:
Every time you change a table, a new metadata file is created and thus an immutable log of metadata files for a table is created, where the Iceberg Catalog points at the the most recent metadata file in the log.
Remember the point about "atomic operations"— This is why it's important.
More importantly, this log of snapshots now enables the following:
Schema Evolution
Time Travel (roll back to a previous snapshot of data similar to how you roll back to an earlier commit in git)
The Metadata Layer - Manifest Files
Skipping "manifest lists" is very intentional, but we will cover that right after. Manifest files serve as the "bridge" between the data layer and the metadata layer. Furthermore, manifest files are essentially the "directions" to where data files within the data lake are located.
Remember when we discussed how the challenge with data lakes is that you have to scan through all the files inefficiently? This challenge is overcome with the manifest file, which contains the following:
path to the data file
snapshot id
partition information
A simple comparison is like going from scanning a list data structure to referencing a data point via a hash table.
The Metadata Layer - Manifest Lists
At a high level, these files are essentially just a list of the manifest files with the following information:
path to the manifest files
what manifest files compose a snapshot
partition information
The Data Layer - Data Files
These are the files you are used to seeing in a data lake (e.g., Amazon S3). These files contain the following information:
path to the data file
format of the data file (e.g. parquet, avro, etc.)
partition information
various statistics about the data
the data itself
These three layers work in tandem to enable efficient data scanning within data lakes, ACID compliance, and various other benefits by keeping a metadata log. All of this is why Apache Iceberg is moving to become the dominant table format for the "data lake house" architecture, with the data lake house architecture being the main pattern most companies are moving towards if they started with a data lake or are considering a data lake.
How Data Contracts Can Leverage Apache Iceberg
If you have been following this Substack, I would assume you are well versed on data contracts and thus won’t go too in-depth. But to quickly recap, from the perspective of data lakes:
Data contracts ensure the metadata (e.g., schema) stays consistent throughout the entire data lifecycle and its workflows.
Specifically, so much business logic and dependencies are created in ELT's “transform” stage, making these workflows brittle.
Rather than reactively resolving issues that surface due to upstream changes, the metadata is used to automate the enforcement of expectations of important data assets.
This enforcement is automated via CI/CD checks within pull requests and other components within the developer workflow.
If you want to dive deeper into data contracts, I highly suggest the following three articles from this Substack:
But what do data contracts look like in conjunction with Apache Iceberg? First, let’s review where data contracts fit within the data stack. The image below (an early preview from our upcoming book) is a generalized overview of a typical data stack, where the letters in black circles represent the various points data contracts can be implemented:

In this diagram, Apache Iceberg would fit within the “OLAP database” for the scenario of enforcing contracts within a data lakehouse architecture. In addition, we would want data contracts at “B” to protect CRUD operations impacting the transactional database and at “C” to protect the data replication of transactional data going into the data lake.
But you may ask yourself, “If data contracts prevent violating data changes from entering the data lake, how can Apache Iceberg help?” While contracts aim to prevent, the reality is that data workflows are much more subjective and require flexibility in how contract violations are enforced. In the diagram below (another early preview from our upcoming book), I want to highlight the “soft failure” workflow where the data asset and contract owners are notified, but the change still goes through.
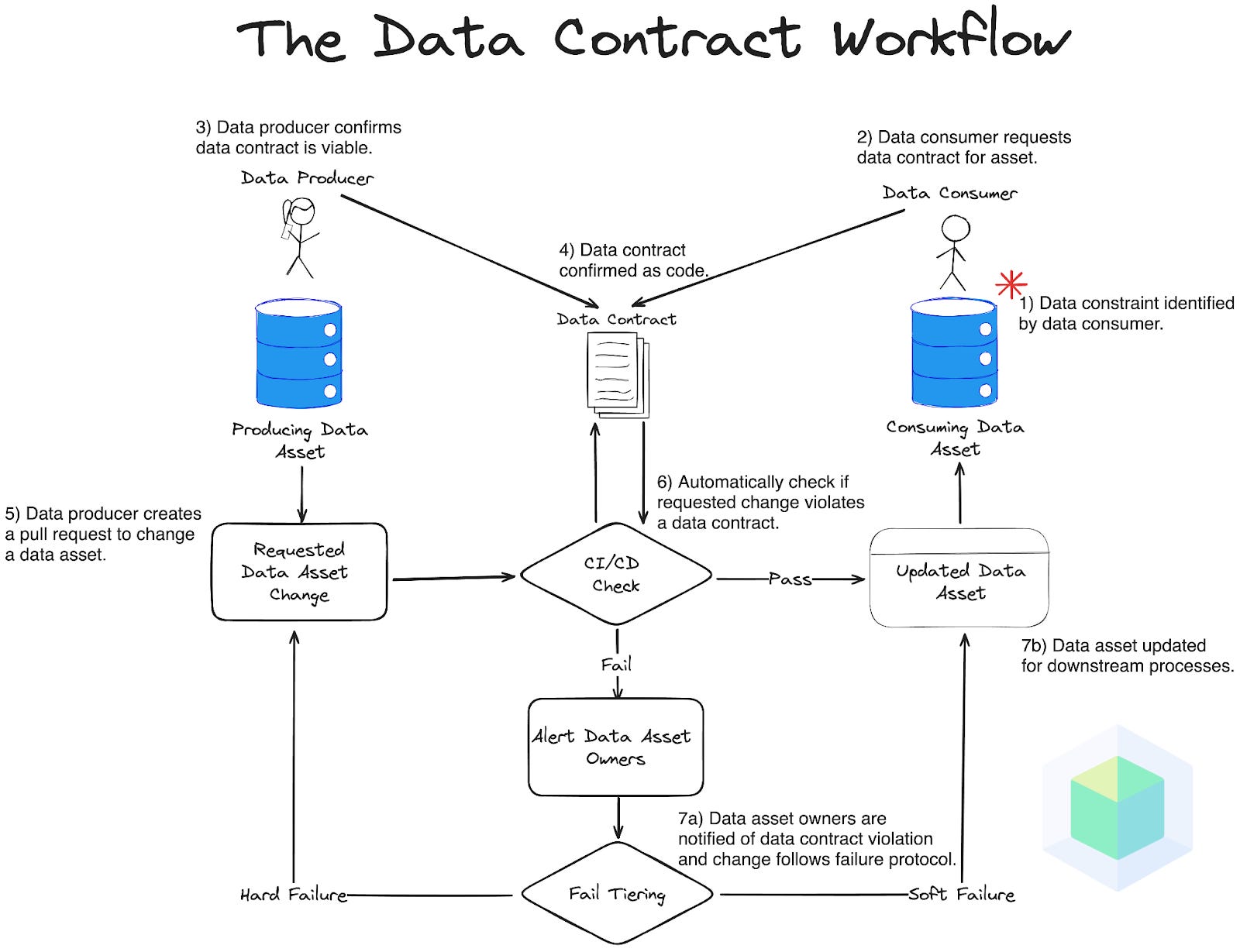
An example would be a breaking but valid upstream change the software engineering team requires, such as replacing a data value for a key user-facing product feature. This also may be the case where data teams are still building buy-in for upstream engineering teams to have contracts enforced on them.
While this upstream change is valid and won’t be blocked, the downstream data team still needs to account for the breaking logic, which can take days or weeks. Without data contracts, this ends up being a silent failure or reaching downstream business stakeholders before the data team is aware, eliciting the dreaded phrase “This data looks off…” With data contracts, data teams can get ahead of this problem the moment the violation takes place— but we can take it further by utilizing Apache Iceberg.
The two sentences below provide one of the clearest value prop statements for Apache Iceberg. Specifically, I want to highlight the bolded section about “time-travel” capabilities as it’s most pertinent to data contracts:
“Apache Iceberg provides immutable snapshots, so the information for the tables historical state is accessible allowing you to run queries on the state of the table at a given point in time in the past, or what’s commonly known as time-travel. This can help you in situations such as doing end-of-quarter reporting without the need for duplicating the table’s data to a separate location or for reproducing the output of a machine learning model as of a certain point in time.”
Source: Apache Iceberg The Definitive Guide, Chapter 1
With the availability of Apache Iceberg’s immutable log of snapshots and the ability to “time-travel,” I propose the following workflow:
Read the metadata the Apache Iceberg catalog stores and document available data assets to enforce data contracts.
Data consumers identify what constraints are important for their workflows and place a data contract.
Violation of a contract:
Hard Failure - Stops the change from even happening (very restrictive and requires buy-in from engineering).
Soft Failure - Alerts stakeholders but doesn’t stop the change (less restrictive, but easier for data teams to implement).
Soft failure triggers Apache Iceberg to utilize “time travel” and “heal” the data to a stable previous version, giving the data team time to resolve the impact of the upstream changes without breaking current workflows.
Thus, this infrastructure aims to protect the trust downstream data teams have built and worked hard to maintain with their stakeholders. Like security, data quality requires layers of prevention to provide comprehensive protection throughout the business. I argue that data contracts and Apache Iceberg can help teams do this.
Further Reading
A huge thank you to Alex Merced, co-author of Apache Iceberg: The Definitive Guide, who provided a technical review of this article's Apache Iceberg section. I highly suggest giving him a follow.
Yet another clear explanation from one of the best communication teams in the data community! We are obviously living through an evolution of data platforms, and reading Chad and Mark is like seeing ahead into the future of data-governance-as-code.
I really like the grocery shopping analogy, thank you.
Also noticed that the link to "The Rise of Data Contracts" is broken.