
Why Data Quality Is More Important Than Ever in an AI-Driven World
The Shift to Data-Centric AI

Note from Chad: 👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and I write about data products, data contracts, data modeling, and the future of data engineering and data architecture. I’ve been hard at work building Gable these last few months, but today, Mikiko Bazeley is taking over and providing a deep dive into the implications of data quality on AI. I had a chance to learn more about Mikiko’s deep expertise in MLOps when we toured Australia together for the DataEngBytes conferences, and I had to have her share her insights in my newsletter. As always, I‘d love a follow and share if you find it valuable.

AI Is Data-Hungry
The truism “You are what you eat” has never been as apt as in machine learning models and products. The impressive proof-of-concepts built by experts and hobbyists alike, along with a growing number of production use cases, have only driven the demand for data.
Good data, web data, free data.
Data that’s structured and data that’s unstructured (especially unstructured).
Junk data, organic & free range ethical data.
Is there really a difference when it comes to delivering incredible experiences and new features with the God-tier models on the market? Isn’t all data “good data” for the purposes of machine learning at this point?
Let’s take a stroll back through some of machine learning’s greatest examples of data-related flops for a quick refresher of how data quality can have, and has had, detrimental (and measurable) individual and societal impacts, at least until those projects were pulled.
When Good ML Went Bad
Most companies aren’t quick to publicize their failings, as retrospectives and post-mortems are used more as internal exercises to prevent future hits to the company’s current share price rather than for external-facing accountability. That’s not to say there aren’t examples, especially in sensitive areas like medicine, education, and civil rights.
For example iTutorGroup, a tutoring company thought to be using ML-powered recruiting software, recently settled a lawsuit alleging that their screening process performed age-discrimination by screening out candidates “women aged 55 or older and men who were 60 or older.” Was a filter intentionally set or could this have been an incident where the training data was biased towards younger candidates, based on past hiring decisions potentially enshrining the prejudices of the hiring managers?
This wouldn’t be the first time that poor design and data collection as well as model training and experimentation design would have failed an ML product. Especially in ways that were detrimental for the individuals unfairly caught up in the dragnets of AI. For example, the growing number of cases of facial recognition being used to wrongfully arrest people of color has started to shed light on how poorly designed and evaluated the models, as well as the datasets being used to train these models, are and the ubiquitous lack of best practices.
Even if the data is “good” from the perspective of reflecting the biases and systemic injustices present in real-world conditions, do we really want a mirror image? For example, do we want to automate into existence a world where inequitable access to medical care is being used to exclude Black patients from being identified as in need of “high-risk care management” programs by hospitals and insurance companies? (Additional links: Loyola Health Law Review, Racial Bias Found in a Major Health Care Risk Algorithm)
Poor data handling doesn’t just hurt “we the people,” it’s also costly.
As an analyst creating financial forecasting models, what if you were using outdated or bad financial data? Aside from inaccurate predictions and forecasts, resulting in poor investment decisions and significant financial losses for the model’s end users, you could end up losing your company customers (and yourself a job).
Are you a clinical director test-driving a new diagnostic tool meant to replace your favorite and expensive radiologist? You’ve just found out that the underlying model was initially trained with mislabelled data and certain instances were tagged with the wrong diagnosis, such as Epic’s Sepsis Model that had to be revamped. Have fun with those malpractice lawsuits.
Data Quality: The Next Big Thing In Generative AI
The irony is that even as we struggle with data quality on easy mode, for analytic or simple machine learning use cases, data quality is the next “big thing” in a future where generative AI, multimodal ML systems, and streaming will become the norm. However, it could be argued that data quality has been the real hero the entire time. After all, the success behind GPT-4 (and even GPT-3) had as much (if not more) to do with their investments in their data as their algorithmic research.
For example, Karpathy’s presentation on the GPT assistant training pipeline highlighted the huge corpus of raw (ugly) data initially used, then an additional corpus of data created by contractors, then additional rounds of manual evaluation and prompt response, during which multiple iterations of models were trained (parts of this process constitute a technique called RLHF, Reinforcement Learning From Human Feedback).
In fact, if you consider all the recent winners and leaders of the generative AI wave, from big cloud enterprise companies to lean and mean cutting-edge startups, it’s clear that the secret sauce was in how they architected their data engines.
The implication is that for companies looking to build AI or use AI as part of their services and core offerings, whether that be developing the next large model (maybe even the next large vision model or multimodal model) or developing an autonomous vehicle service, the most important area of opportunity is developing the processing and infrastructure for systematically engineering data quality into their pipelines. Building continuous improvement and iteration, whether the data is structured or unstructured, is a key prerequisite to ensuring a company isn’t left behind and becomes a relic in a data-centric future.
Machine learning and generative AI aren’t going to kill your business. Dall-E and Midjourney could have been the death knell for Adobe– instead, more than 1 million images have been generated using Firefly.
One of the worst mistakes companies and data developers could make is thinking it’s already too late to leverage their data to create powerful products and services. Anyone who’s been involved in data governance efforts at an enterprise company with a legacy stack and a sprawl of data sources would be hard-pressed to see how they could close the gap between themselves and their more svelte competitors.
Yet astute data developers know they shouldn’t fear the reaper – the emergence of Gen-AI is pushing companies to acknowledge the poor state of their data, especially as the shortage of data for training LLMs is on the horizon. Running out of training data, especially as the foundation models keep growing and consuming publicly available and high-quality data at a rate far faster than is being replenished seems like a weird problem and an opportunity.
How? For starters, most companies and organizations can’t afford the years and millions of dollars of funding to create the equivalent of Google Brain or DeepMind, exploring new model architectures that may offer only incremental improvements over all the LLMs and foundation models available on the market (both proprietary or open-source). But data is something all companies have in abundance: data that is specific, private, and custom to the company and its use cases. And even if you don’t have a readily available dataset, you can always buy data the way Open-AI, Google, and Meta have (amongst many others).
Companies that have invested in enabling a data flywheel at the product level know that they’ll be okay, especially because the next challenge with the democratization of LLMs will demand differentiation at the data level, especially of higher quality data for fine-tuning models (rather than swamp loads of poor quality data).
Making It Rain With High-Quality Data
You’ve bought into the possibility that data quality can be impactful, not just for the current and most prevalent analytic and machine learning use cases. You’ve also acknowledged that there seems to be a relationship between your company’s current level of data quality and the myriad opportunities to capitalize on the recent advancements of generative AI. And you’re eager to leverage the data you already have (especially since it means dodging the copyright issues other companies seem to be running into) and ready to make the necessary investments in data quality.
The question then becomes: What drivers of data quality in the machine learning lifecycle can you influence?
How Data Becomes An ML Model
In order to answer this critical question, we’ll need to define data quality (especially from the machine learning perspective) and the specific problems that data-centric AI addresses (and how).
Data & ML Aren’t Just Software
It’s worth starting with the different touch points between data and code in typical software systems and projects. Quite simply, the data is secondary. The application logic is primary.
What do I mean? I mean that the actual logic of the application or microservice doesn’t depend on the data, its structure, its schema, or the distribution of its values. If you want a website that loads fast and lists all items being added in a specific order or based on filters, you don’t really need to know too much about the items being listed other than the associated metadata or attributes that need to be called or returned. You’re not necessarily changing every site page dynamically depending on the items themselves, and even if you are, it’s still based on some set attribute like category (“Baby Supplies” versus “Arts and Crafts,” or “Workout Equipment” versus “Wood Working”). You could take Target’s entire SKU catalog and swap it with Amazon or Walmart, and as long as the data specs match up, you’re good. (Sans special products, prices, and rewards. IYKYK.)
Data Drives ML, Which Drives Code…
Effective data management, particularly in the formulation of a well-suited training dataset, holds significance for enhancing model performance & improving training efficiency during pretraining & supervised fine-tuning phases. – [2312.01700] Data Management For Large Language Models: A Survey
A machine learning model is its data and all the sets of data required to train (or fine-tune) a model. The three types of data artifacts created throughout the machine learning lifecycle where quality is key include the:
Training Data
Inference Data
Maintenance Data (including metadata).
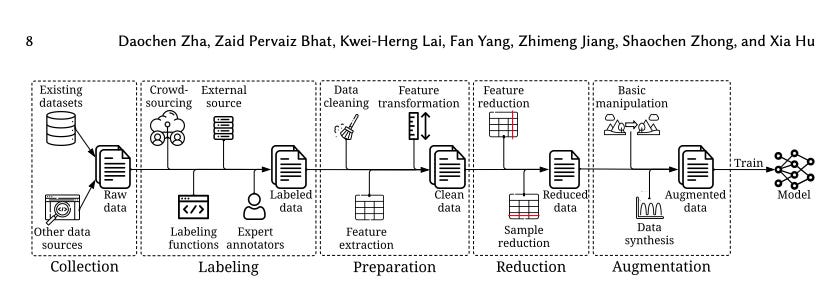

How does quality play a role in each of these datasets?
Training Data Development
Data Analysis & Feature Engineering
Manual exploratory data analysis is an important process (and rite of passage for new data developers) because oftentimes, that’s where data quality issues are initially identified. Early exploration can often yield valuable information on the relationships of different entities and processes within the business to each other. Scatter plots, heat maps, bar charts, correlation analysis, etc., can reveal opportunities to apply transformation to the data in the form of feature engineering or the creation of inputs to downstream machine learning models. Well-defined, normalized, and consistent data (as well as documentation) can speed up this process significantly, cutting down on back & forths.
Oftentimes, EDA is the stage that determines whether an analytic project goes on to become a machine learning headache. Consequently, the most common advice around starting machine learning projects, especially if someone doesn’t have the infrastructure already, is “don’t.” As in, “Don’t go straight to machine learning, first see if you can manually analyze the dataset and derive insights and signals manually from good ole fashion EDA.” Eventually, the insights are turned into features, or inputs to machine learning models, typically represented as columns (where instances are rows).
Model Training & Fine-Tuning
Once a dataset has been structured and transformed, it becomes the training dataset that an algorithm will be applied to in order to create a machine learning model (for supervised learning), a version of the algorithm where the weights have been learned and can be frozen to be used as part of a pipeline.
Fine-tuning, which has been the rage in the ML side of the world, is an extension of the same idea. Although deep learning and generative AI have been able to tackle much of the gnarly process of processing unstructured data, that’s not to say that great-quality data is no longer important. It’s become even more important as specialized use cases require additional fine-tuning (and custom data) on specific tasks rather than generalized and shallow tasks like text summarization.
Inference Data Development
Model Evaluation
We need to know that these models work, regardless of whether they’re simple, classical, supervised XBG Boost classifiers or the latest and greatest foundational model. We must ensure they work in real-world conditions, not just toy sandbox scenarios. We also need to ensure the transformations and assumptions we’ve applied in training or fine-tuning these models reflect the battle conditions the model will be tested against.
Model Inference
Finally, whether we’re prompting models, uploading images and videos, or connecting them to real-time stock market feeds, we need to ensure the data coming in for the model to perform inference on (or predict or take action on) is in the right shape, format, distribution for the model to be able to perform. The model was trained and created under certain assumptions – deviations will either break or slow your service, or at the very least, send tons of notifications (assuming monitoring has actually been set up).
And Code Can Drive Data… Badly
In order for data to exist, it must be generated (or collected or transformed) by applications, APIs, and or microservices. Data is an artifact of processes, objects, and people being captured in code. Oftentimes, this is the start of the problems experienced by most data consumers (which would classify many data scientists and ML engineers).
Effective machine learning can’t be done if:
The data doesn’t exist in the first place.
The data isn’t trustworthy.
Especially given how long developing a model can take in the data preparation stage alone, when a dataset is constantly changing, is ill-documented, and has no owner, the data scientist can end up spending most of their time patching problems in their data sources.
The data scientist, ML Engineer, or AI developer experiences the bullwhip of poor quality issues originating at the source.
Feed Your AI The Good Stuff
It probably hasn’t passed your notice that while I’ve waxed lyrical about the importance of data quality in the machine learning context, I haven’t actually defined it. Let’s fix that.
What is a machine learning model doing?
“At the heart of any machine learning model is a mathematical function that is defined to operate on specific types of data only. At the same time, real-world machine learning models need to operate on data that may not be directly pluggable into the mathematical function.”
- Valliappa Lakshmanan, Sara Robinson, Michael Munn (Machine Learning Design Patterns, O’Reilly)
Machine learning models and systems are meant to mimic many of the same manual processes humans do but better, faster, and more efficiently. The lowest-hanging fruit kind of machine learning (like time-series forecasting or other supervised models) looks at the past, fits patterns to trends, and then projects those trends and patterns to the future (or to other scenarios). They’re naive. They assume that what you present them is the picture of the world, the slide they should look at, no more or less.
Defining “data quality” for ML
So how do we measure the quality of data for machine learning models? A machine learning dataset’s quality is measured by the quality of its predictions.If a model is its data, and the model is doing terribly, then the quality of its dataset is correspondingly terrible. How can a dataset be poor quality? To quote Chad and Mark:
Poor quality data is the symptom of the data, representing a technology and or process, diverging from the real-world truth. [Usually due to an] organization’s ability to understand the degree of correctness of its data assets & the tradeoffs of operationalizing such data at various degrees of correctness throughout the data lifecycle, as it pertains to being fit for use by the data consumer.

The entire point of a model is to predict or trigger an action in the real world or in some subset of the real world. The dataset must come as close as possible to resembling the process being represented in the data.
Measuring ML Data Quality
How can we measure the degree of quality? Do we need an entirely different lexicon because machine learning isn’t analytics and vice versa? Luckily, many data quality measures used in the DataOps world have commensurable measures in MLOps.

In a future post, we’ll get into the nitty-gritty of these measures and how they take into account the changing and dynamic temporal nature of data, but for now, we can summarize the concerns of data quality in production machine learning as:
Data Label Consistency – Are the instances of the data properly (and consistently) labeled?
Class Representation – Are the target classes properly (or necessarily) proportionally represented?
Drift (especially data drift) – Is the data being refreshed and kept in sync with the population the data is drawn from?
Systematically Engineering Data Quality: The Shift to Data-Centric AI
Data engineers and developers must be quite chuffed to know that data is SO HOT (again), especially since the pendulum was previously pointing to Model-Centric AI (MCAI). How does the Data-Centric AI (DCAI) approach differ from the Model-Centric AI way?
DCAI vs MCAI
“Model-centric AI is based on the goal of producing the best model for a given dataset, whereas Data-centric AI is based on the goal of systematically & algorithmically producing the best dataset to feed a given ML model.” – Introduction to Data-Centric AI
In the Model-Centric AI period, the normal approach to improving a model was some combination of tossing money at the problem by adding more data, fixing data in a Jupyter notebook when issues were identified, or doing a combination of cycle through different model architectures and tuning hyperparameters. All for the model to fail six months later in production after being enthusiastically announced at the last company town hall. Alas, no bonus. As teen minstrel Olivia Rodrigo observes, “It’s brutal out here.“
DCAI In Action
The Data-Centric approach to engineering data quality is part automation and part domain expertise, and is focused as much on understanding the issues within the data as fixing them. It includes:
Detecting and identifying issues with data labels – Performing outlier detection and removal, error detection and correction, establishing consensus, etc.
Thoughtfully increasing the data size – Adding data through sampling, data augmentation, data collection, etc.
Transforming and curating the data – Through feature engineering and selection, more advanced workflows like active learning and curriculum learning.
All for the purposes of developing high-quality training and inference datasets, as well as being able to perform data maintenance.
The Relationship of Data Size To Data Quality
Part of the early promise (and misconception) of deep learning was you could toss any dataset (especially unstructured data) at a neural network architecture and you could skip the data quality, cleaning, and feature engineering steps.
You’re forgiven for being quite wrong.
Throwing a lot of dirty data ensures a poor-performing model, especially when all the resulting time spent cycling through different model architectures and hyperparameters could have been spent improving the upstream data source so all models are improved.
And the requirement for high-performing models is no longer half the internet. The higher the noise in a dataset, the more data you need to compensate so that the model doesn’t overfit or overlearn the training dataset. The graphs below are from Chad and Mark’s upcoming O’Reilly book on data contracts, which highlights Andrew Ng’s comparison of various data conditions for predictions.
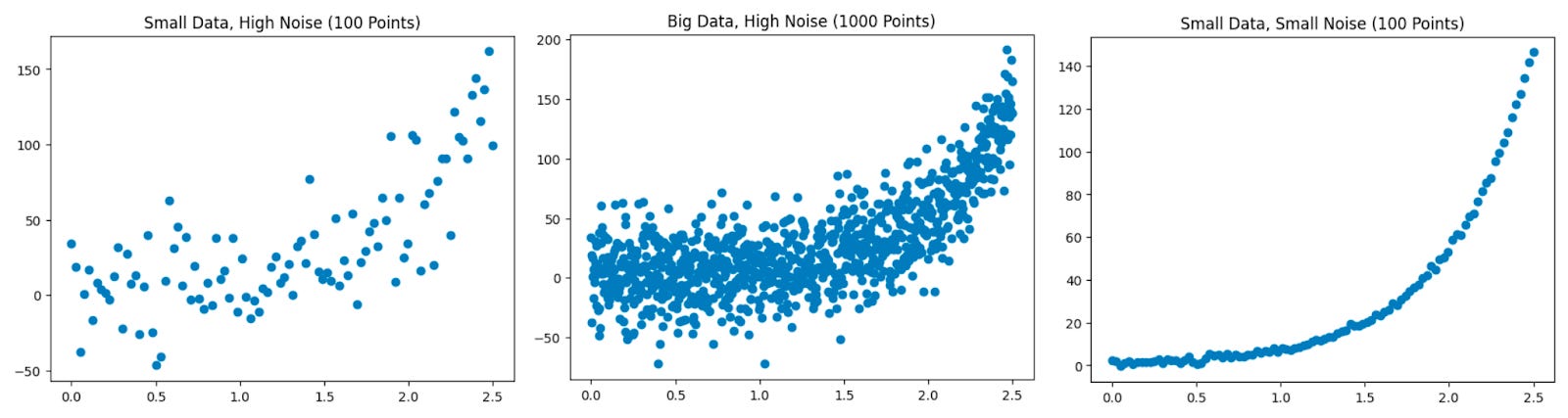
And with the commoditization of data science workflows and tools, the ability to engineer high-quality data to produce high-quality models is more accessible than ever.
Conclusion
Data quality can have, and has had, detrimental impacts on machine learning projects with measurable negative societal and individual impacts.
Advances in Generative AI are highlighting the increasing and aggressive demand, as well as potential shortage, of high-quality data.
There are specific ways that data quality impacts the machine learning product development cycle, including the ongoing maintenance costs of ML pipelines.
 | A guest post by
|
"especially because the next challenge with the democratization of LLMs will demand differentiation at the data level, especially of higher quality data for fine-tuning models"
What is "demand differentiation" at the data level?
Wonderful article ... thank you for sharing! Where are people getting high quality web data from? Scraping it themselves?