

The Existential Threat of Data Quality
The Existential Threat of Data Quality
And Why the Modern Data Stack Can't Solve It

For those who are outside of the logistics and freight industry, it can be challenging to understand the amount of operational complexity in the fulfillment of a single shipment. Convoy adds complexity to the traditional freight lifecycle through the addition of an auction-based marketplace. Shippers submit RFPs to brokers, brokers forecast capacity and bid on RFPs, Shippers award tenders, awarded shipments are priced and made available on the marketplace, carriers bid on and win shipments, carriers deliver shipments to facilities, and contracts are fulfilled. Even this model is overly simplistic. 1000s of branching paths occur at virtually every stage of the shipment lifecycle, and Convoy is always adding new nodes in the graph of interacting entities by introducing products like Convoy Boost (Marketplace for Brokers) or Convoy Go (Drop and Hook Trailer Marketplace).
Convoy’s key differentiator compared to other freight brokers is data. The amount of data we collect about shipments, shippers, and carriers through our first and third-party sources is unparalleled in the world of brokers This data forms the backbone of the company. It allows us to efficiently operate a tech-driven freight marketplace at scale, powers machine learning models that drive pricing, offer relevance, RFP simulation, and shipment success predictions, and facilitates rapid experimentation across a variety of product lines. Due to the complexity of this data, Convoy has invested heavily in both data architecture and data personnel. In this chart by Mikkel Dengsøe that plots the distribution of engineering to data hires at 50 of the fastest rising US-based startups, Convoy ranks an impressive 3rd on the list:
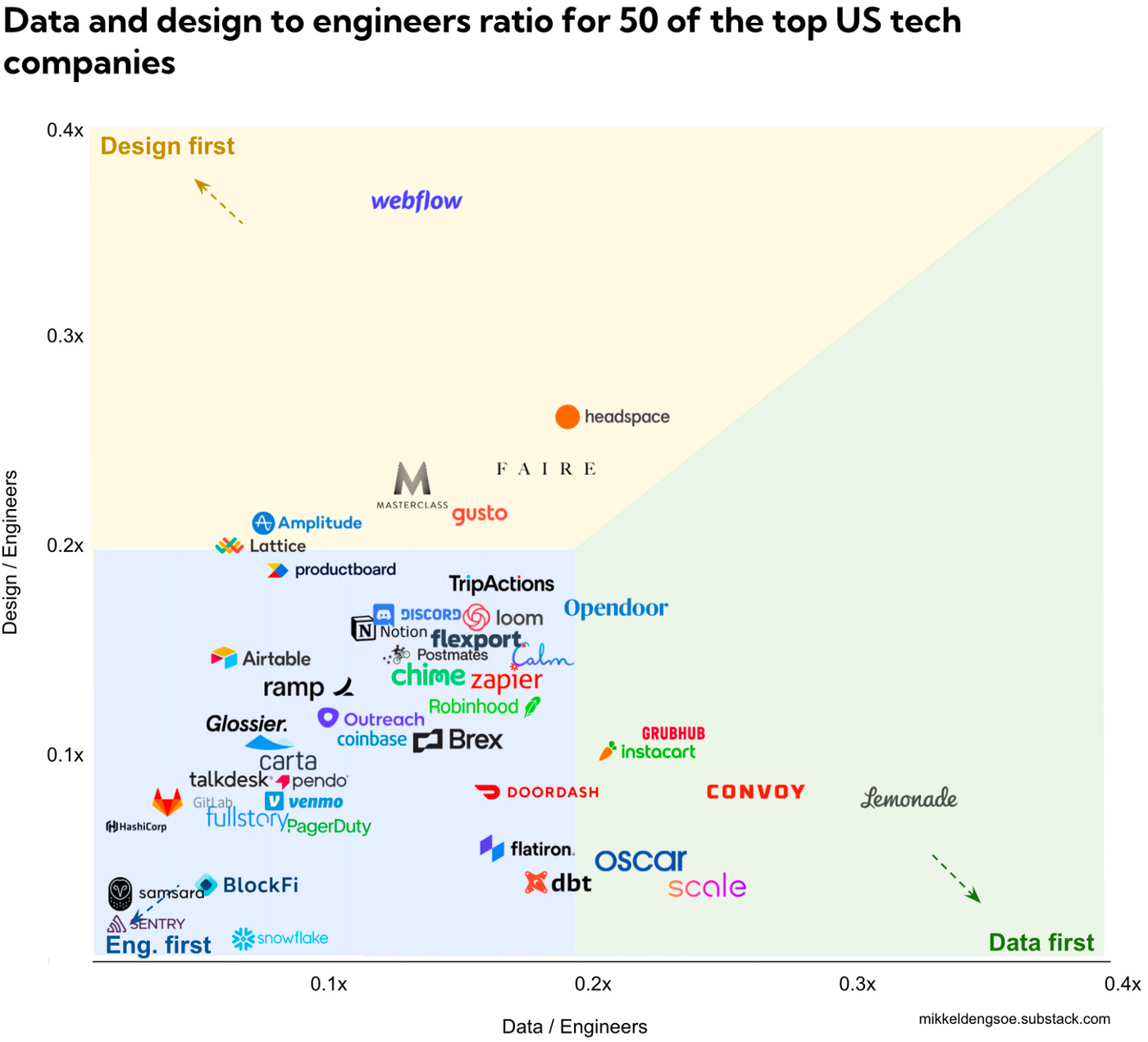
The data team’s ability to leverage data in analysis, build ML models, and run experiments is crucial to Convoy’s ability to succeed in the long run. Despite this, Data Quality was by far the biggest problem the data team faced on a day-to-day basis. This is not a unique characteristic. Data Quality remains an existential threat in virtually all data-driven organizations, and as the Modern Data Stack (MDS) continues to evolve this problem appears to be getting worse. But why?
At fast-moving, data-heavy companies, data models which form the foundation of the most important metrics, dashboards, and machine learning features are written on top of legacy SQL with unclear ownership, built on data extracted from production tables, which operate as the implementation details of production services. Over time, data has outgrown the initial use case of ‘provide a dashboard for an executive’ and spirals into hundreds or even thousands of models in only a few short years. Many of these data models reuse the same data with a different name or reference unmaintained tables. Good testing is rare which makes debugging challenging. Teams struggle to understand the source of truth for important data and spin up their own bespoke tables for ad-hoc questions resulting in ‘data spread.’ When pipelines break it is not clear who should fix them. When production tables change, incidents that impact production ML models significantly impact business operations.
Beginning in December of 2020, the Data Platform team, Convoy’s internal infrastructure platform organization set about searching for a solution to the largest data quality issues that impacted the business. Our goal? To solve data quality holistically through investments in both technology and cultural change. After a quarter of investigation, we identified 2 major causes of Data Quality: Upstream & Downstream Issues.
Upstream Quality
The majority of analytics data at Convoy originates from CRUD events emitted by services. For example, each time a new tender is created by a shipper, the tender service generates a row in a corresponding production table along with many details which are germane to the day-to-day operations of the application and Convoy’s business. This data is then captured using a streaming CDC operation. Once the data lands, it is transformed by data engineers into ‘blessed’ tables that have been aggregated and categorically organized for meaningful analysis. Data consumers, specifically data scientists and business intelligence engineers then leverage tooling such as dbt to build tables consisting of metrics and derived attributes to answer a variety of business questions that serve analytics, experimentation, and machine learning use cases. This pipeline should not look unusual to any business bought into the Modern Data Stack.
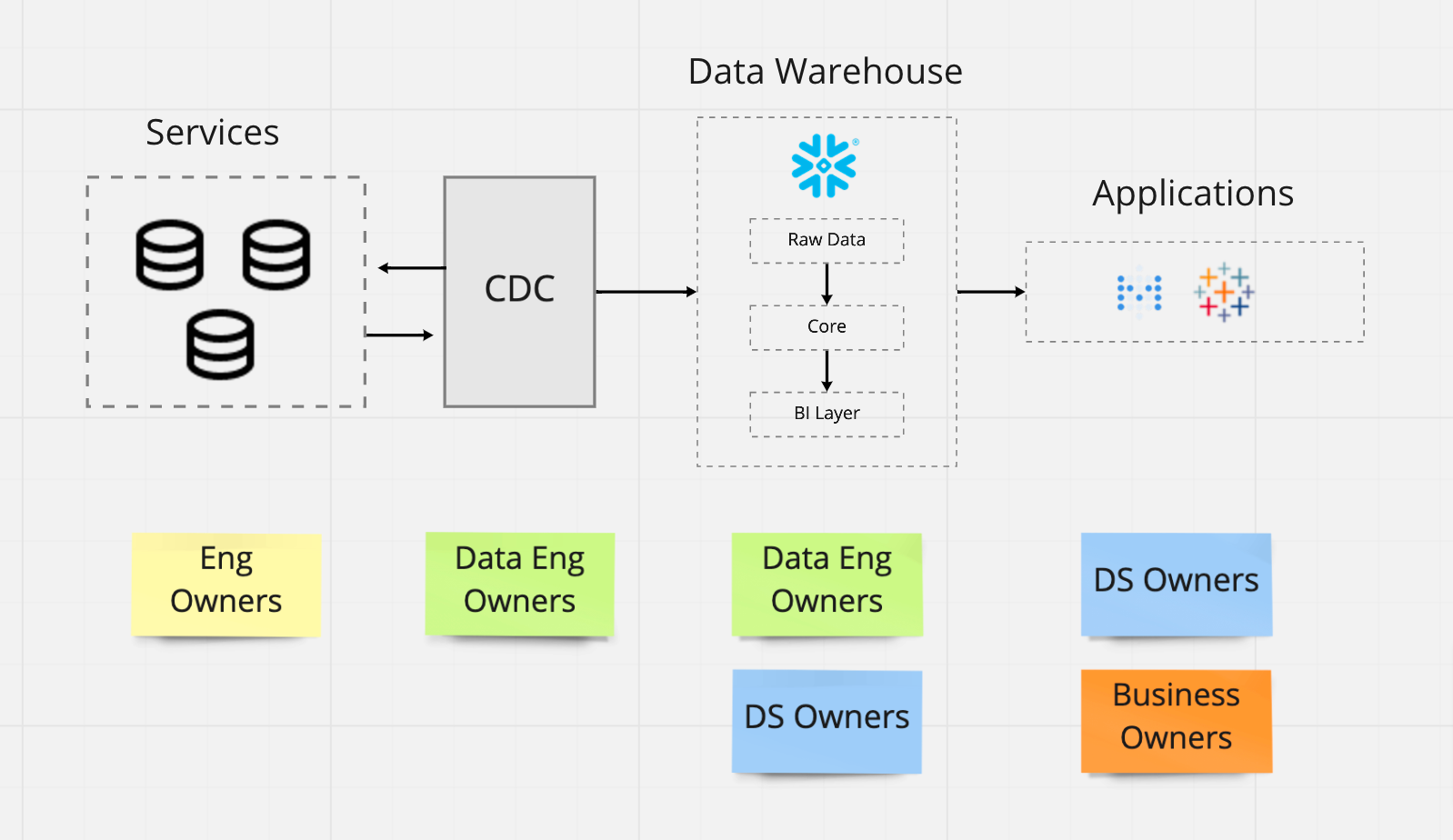
However, there are a few major problems with this workflow.
First, the CDC process records the internal implementation details of the service. This data was never intended for analytics, and the strong coupling between these events and business-critical functions results in a large operational overhead. When a software engineer decides to alter their services’ production database by dropping or renaming a column, it could (and often does) break machine learning models or important downstream reports. When this happens, data consumers and data engineers set off on a wild goose chase to identify the offender and implement a fix. In many cases it is challenging to detect an issue has even occurred due to important tables lacking tests, good documentation, and ownership.
When something downstream breaks because of an upstream change, who's on the hook to fix it? The business consumer using the table? The data scientist that built the model? The data engineer who created the pipeline? Or the software engineer who owns the service?
The delineation of ownership responsibilities was very rarely established, with each group wanting to push 'ownership' onto someone else so they can do the jobs they were hired for. This resulted in an increasingly messy DW with a rapidly worsening problem over time.
TL, DR: Production services and analytics/ML are tightly coupled. The implementation details of production services were never intended for analytics use cases, and engineers actively discourage taking production dependencies on this data.
Downstream Data Quality
To reiterate an important point above: The data collected by CDC mechanisms were never intended for analytics. This means the data must be significantly transformed before it can be leveraged by the business. Data engineers, Data Scientists, and Analysts often play the role of translators - understanding how to recreate real-world events or concepts using CDC components manipulated through SQL. Because most data scientists or analysts are not trained in data architecture or data warehousing best practices (And this makes sense, their actual job is building statistical models, grokking interesting business phenomena, and generally delivering business value) queries can quickly become 500+ line monstrosities with double-digit JOINs. These tables are rarely documented comprehensively, and in many cases are simply not producing the intended output.
As important business concepts are created and centralized, other teams take dependencies on these ill-conceived tables, and more teams take dependencies on THOSE tables. This data is used to train machine learning models, analyze experiments, and measure week-to-week business outcomes. With tools like dbt rapidly accelerating the rate of table development within any modern data-driven organization, what begins as a problem to solve later morphs into a monster of unimaginable complexity. The data warehouse is a quagmire, virtually impossible to understand or penetrate. Data Scientists can spend more than 60% of their time on data munging in this world, pushing quality ever further to the side as demands from the business mount.
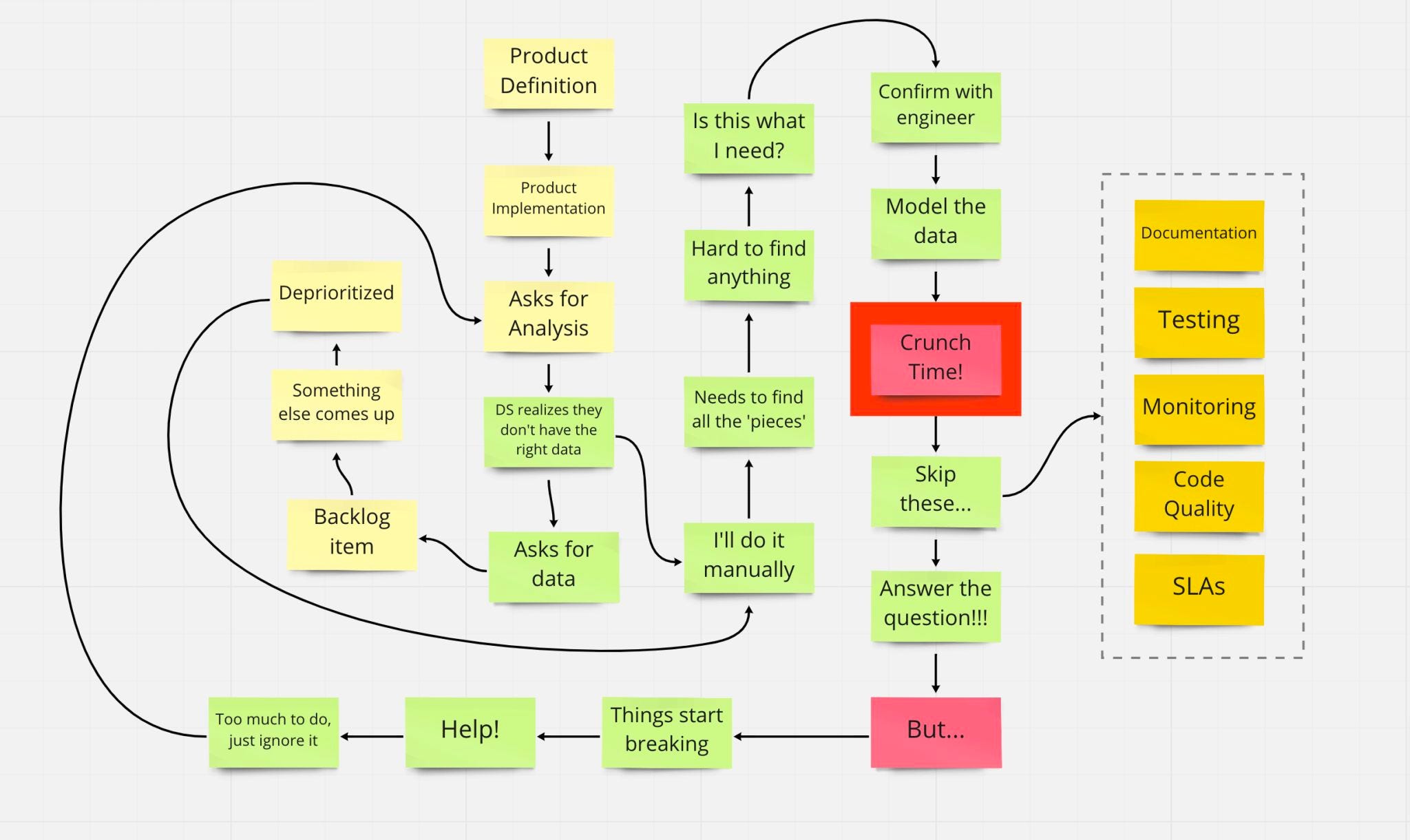
The skillsets of modern data consumers and the requirements to conduct analysis and machine learning at scale are diverging. Data scientists are becoming less familiar with data architecture best practices and rigorous software engineering standards. Despite this, tools in the modern data stack require data teams to take ownership over data models and understand production code paths.
This dichotomy has resulted in a bizarre state of existence for many data scientists and analysts. They are hired for their ability to derive insights from data and build models, but spend most of their time debugging poorly written SQL queries from 4-5 years ago, diving into undocumented production tables to grok how a particular CRUD event is being emitted, and messaging data engineers to understand 'why is this test failing?' or 'what does a row in this table represent?'
When Upstream and Downstream Data Quality issues combine, the result is an extremely problematic data landscape. ETL/ELT systems dump data never intended for analytics over the fence, where downstream consumers attempt to reverse-engineer the current state of the world in SQL. The number of models gradually spirals out of control as teams need to move quickly and leverage tools that, while easy to use, are not rooted in the semantics of the business.
The ‘Modern Data Stack’ is Broken
The modern data stack (MDS) has a few distinct characteristics that have allowed for the rapid development of new startups. Centered around the Cloud Data Warehouse (Snowflake, Databricks) MDS-based companies focus heavily on instrumenting front-end applications (Mixpanel, Snowplow) piping a wide variety of data assets into the Data Warehouse as quickly as possible (Fivetran, Airbyte) transforming the data flexibly (dbt) and either leveraging the data to accomplish business tasks (Hex, Eppo) creating metrics (Trace, Transform) or pushing it back into 3rd party tools via reverse ETL (Census, Hightouch). However, none of these tools addressed either Upstream or Downstream Data Quality issues. This means the Data Warehouse is still fundamentally untrustworthy, virtually impossible to navigate, and constantly breaking.
To reduce the pain around Data Warehouse quality, categories like Data Catalogs (Stemma, Alation) sift through the mess of the DW, and observability platforms (Monte Carlo, Bigeye) allow central data engineering teams to serve as the command-and-control center for detecting breaking changes and fixing them. But even with this, nothing addressed the root cause: The ETL process is reactive instead of active. If data with little ownership and no quality controls flow into the data warehouse, there are no tools in the world powerful enough to prevent the accumulation of the technical debt required to work in or around such a system.
While the technology within the modern data stack is each on its own incredibly valuable, you cannot build a house on ruined foundations. The Data Warehouse itself and the mechanisms by which the Warehouse evolves are irreconcilably flawed to their core. There is no magic wand solution, no fancy technology that will usher data teams to the promised land. But there is an answer that is fundamentally cultural and primarily a problem of collaboration: Treating data as a product.
Discussing the why and how of data products is a topic for another day. However, the focus of this newsletter will revolve around exactly these questions:
What exactly is a data product?
How do data products resolve Upstream & Downstream quality?
What changes do we need to make to treat data as a product?
Who needs to buy into such a system?
Each of these questions has answers which are rapidly developing. In this newsletter, I will be talking to Data Product Managers from ‘ahead-of-the-curve’ companies to understand how they have shifted to a data-first culture, the technologies they use to maintain this system, and helpful tips for others looking to get into the space. I believe that resolving these fundamental Data Quality issues is not only possible but required if the promise of the Modern Data Stack can truly be fulfilled.
Talk again soon.
-Chad
Great read Chad, easy to follow and compelling!
Great read and the most important topic is that it is a organizational topic in its root. Data quality issues mostly originate from the sources, source processes and impact the data warehouse and the analytics downstream. As outline the separated ownership of source system and reporting and analytics and an overarching data quality issue is the problem constellation. There needs to be organizational function on top of both data quality issues and the impact can be elevated to, to take a decision if the efforts on change on the source are justified and need to be done.