
The Death of Data Modeling - Pt. 1
And why it must be resurrected in the Modern Data Stack

👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and every week I talk about data, data products, data modeling, and the future of data engineering and data architecture. In today’s article, I will be diving into data modeling - why I think it’s critical to any data infrastructure, and why it needs a revamp for the 21st century.
Tags: data modeling | data engineering | data strategy | Modern Data Stack
Last week I made a post on LinkedIn about data modeling which got a fair bit of traction. It began in the following manner:

Over 100K saw the post, more than 1000 liked it, and over 100 people left comments. Clearly I had touched a raw nerve! Many data practitioners in today’s day and age feel that something is amiss in 21st century data modeling but can’t exactly explain why. The Modern Data Stack seems to be drifting further and further away from robust semantic data modeling, replaced by a tangled mess of spaghetti SQL and queries. In this post, I explore why these problems came about and what we as a data industry can do to fix them.
What is data modeling and why is it valuable?
To begin, what exactly is data modeling?
Data modeling is the practice of designing the structure of data and manifesting relationships amongst data sets and objects. Philosophically, data modeling is useful as an abstraction that bridges the gap between the data we collect and the real world. Semantic concepts - entities, their behavior, the relationships between them, and their properties- modeled effectively in the Warehouse provide an environment for data consumers to explore the edges and nodes in this semantic graph and build agreed-upon derived concepts/metrics.
As an example, I Chad Sanderson am a unique entity of the class [person]. I have specific attributes such as [age: 32], [height: 5’9”], [weight: 155 pounds], and other properties. I regularly interact with other entities, like My Apartment of the class [home], or My Car of the class [vehicle]. I also interact with others in the person class. I have a relationship with the person My Girlfriend called ‘romantic partner’ and a relationship with the person My Father and My Mother called ‘parents.’ The evolution of these relationships between objects are driven by events. I might book_a_vacation [destination: Manila, companion: My Girlfriend, duration: 1 month] and then hire_a_dogsitter [fee: $1000, duration: 1 month, company: Dogs R Us].
These relationships contain information about who I am as an individual, how I navigate the world, the decisions I have made, and the history of those decisions. The more comprehensive the data model, the easier it is for others to ask thoughtful questions about my behavior and generate quick answers.

The most important aspect of effective data modeling is that it is driven by semantics. You do not need to be a software developer, data scientist, SQL expert, or data engineer to understand how data flows through a well-modeled Data Warehouse. In the same way a grade-schooler could easily follow the model I described above, so too should anyone at your company be able to understand the historical behavior of any entity, grok the relationships between entities, and generate queries derived from semantic concepts without a data professional blocking the way.
What does the world look like today?
In the era of the Modern Data Stack, it appears a new wave of tech-first companies have moved beyond robust data modeling. According to Timo Dechau (Founder of Deepskydata) having a well-designed data model is more than just rare:
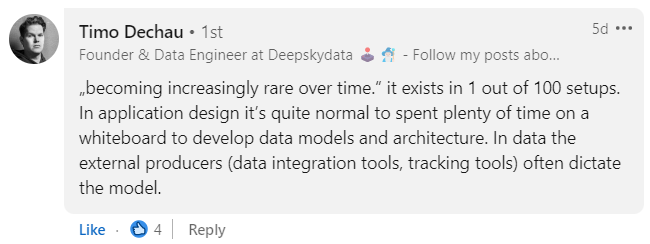
Today, data infrastructure is typically a categorical mess. ELT (Extract, Load, Transform) systems pipe in data assets from a variety of tools and applications with no context:
Front-end tracking data from UI-based instrumentation platforms like Amplitude, Heap, Mixpanel, and Snowplow
Data dumps from 3P tools like Salesforce, JIRA, Workday, and Zendesk
1st party databases like PostgreSQL
etc…
This data is combined post-hoc into a Core data layer which is often managed by a centralized data engineering team.
While this enables data teams to move rapidly, without a strong data modeling culture it creates a number of problems and perverse incentives which lead to data debt and decay:
The Problems
1. It separates the producers of data from the onus of ownership or quality. Software engineers can afford to throw data over the fence to data engineers or data consumers with the expectation someone will figure out how to model it all later. This results in some data being impossible to model and in other cases the logic facilitating JOINs and aggregations is complex and hidden behind layers of institutional knowledge. Pockets of business-logic-awareness form within the business which breeds distrust and significant duplication.
🔥Bonus problem: There are always many more engineers than data professionals in a company. Those engineers build services with lots of data. If data is dumped with no modeling or governance into the Warehouse, it inevitably results in duplication and sprawl!
2. Data Engineers are forced to be 'middlemen' between data producers and consumers. Data engineers often build the initial core layer in a Data Warehouse (After all, who else is going to do it) and as a result they are stuck maintaining this layer through a never-ending number of service tickets as new pipeline requirements emerge. Because data engineers often operate centrally across many teams, they lack a deep enough understanding of the business to model data appropriately and lack the manpower to keep up with an ever-changing business and all its data needs.
3. Time to insight is extremely long. Data consumers spend days or even weeks trying to understand how to unify entities, comprehend undocumented business logic, parse through nested JSON, talk to software engineers to make sense of how a production table is generating a particular field, and so on. Executives and product owners ask simple questions for data scientists and analysts to say ‘I’ll get back to you in a week.’ Questions like ‘what does a row in this table represent?’ are common.
4. Data is Reactive versus Active. As data needs emerge, consumers must leverage what exists in the warehouse even if that data is unsuitable for solving new business questions. The data model evolves from the Warehouse out, instead of from production in. As gaps emerge (and they will) the result is frustrated data consumers and data engineers who are stuck in the crossfire.
In short, without modeling a Data Warehouse quickly becomes a Data Swamp held together loosely by the work of a few heroic data engineers. Too often teams confuse this chaos as either 'normal' or the fault of a data infrastructure team that hasn't been doing their jobs. In reality, it is a result of years (sometimes decades) of data debt. While it is possible to establish some semblance of a structure by throwing bodies at the problem until people stop complaining, for all but the most well-capitalized businesses in the world this solution is hopeless and unreachable. "We can just hire more data engineers" is becoming a running joke among platform leads.

So why is Data Modeling ‘dead?’

As Magnus states above - Data Modeling has been common practice for decades. Why is it that in the 2020s modeling appears to be an forgotten language, spoken only by the most ancient data architects shrouded in robes and hunched over a tattered copy of Corporate Information Factory, reading by candlelight?
In my opinion, it comes down to 3 primary factors:
The proliferation of Agile
The shift to engineering-lead organizations
Implementation Friction
Agile
Agile rose to prominence in the mid-2000s born from a need to deliver iterative software releases safely. One reason Agile development (and by extension DevOps) was embraced by the software industry was that it had clear connections to business value and tangible outcomes. Namely iteration speed, optimization, and continuous improvement of the product. It was not difficult to understand why this approach was radically better! These are concepts any business leader can understand and empathize with.
The Agile Manifesto had the following four key values:
Individuals and interactions over processes and tools.
Working software over comprehensive documentation.
Customer collaboration over contract negotiation.
Responding to change over following a plan.
Unfortunately for the aforementioned Data Architects, no such movement ever manifested for data. Legacy Data modeling is an extremely slow, laborious process that is gatekept by a few framework and data specialists. In the age of Agile, such a high barrier to entry to test, deploy, and drive iterative business value is a no-go. It violates virtually all tenants of the Agle manifesto, and for that reason (explicitly stated or not) has found itself pushed to the wayside.
Takeaway: In order for data modeling to make a comeback it must embrace Agile. The development of the data model should be iterative, collaborative, and most of all - fast!
The Shift to Engineering Lead Organizations
In the nascent days of the Modern Data Stack, it is becoming far simpler for software engineers to stand up Data Warehouses in the cloud and push data from a variety of sources via ELT. At many top-tier startups and early/mid-stage IPO’d companies the initial data infrastructure was created by the software engineering team, not the data team! These software engineers, while technically gifted and incredibly speedy at infrastructure development have often never heard of Data Modeling principles, nor have they read Data Warehousing textbooks from the 90s and early 2000s, and many only have the loosest familiarity with names like Bill Inmon and Ralph Kimball (And why would they? Their job is to build software, not become data historians).
It is very rare to see a Data Engineer or Data Architect among the founding team of even the most well-capitalized startups!
While I would certainly love if founding DNA of early-stage companies shift to become more data-focused, it’s unlikely. The goal of any seed-stage or Series A (and oftentimes Series B) company is not to develop a robust data environment, it’s to build and sell great products as quickly as possible. Often there isn’t enough data at these early stages to justify hiring a full-time data specialist anyway. By the team the data team is brought in, the foundational Warehouse is already in ruins, and it is difficult for data engineers to come above water while dealing with the constant deluge of service tickets. A true data model never has the opportunity to evolve.
Takeaway: In order for data modeling to be adopted longterm, engineers and business/product teams must be able to create a solid foundational modeling environment before the first data hire. I call this ‘falling into the pit of success.’ Good data modeling should be the default, it should be federated, and it should embrace engineers and business teams as users.
Implementation Friction
A common refrain I hear when discussing data challenges at modern tech organizations goes something like this:
“Yes, this all sounds like a problem! But doesn’t Data Mesh / Data Vault / Data Whatever solve that? Data teams need to just read [some book] educate themselves on the proper methodology, find a business case and implement it.”
Easier said than done.
Before I transitioned to big data, I worked in a field called Conversion Rate Optimization (CRO). CRO is an intersection between quantitative and qualitative analytics, experimentation, and UX Design. The goal of any CRO-pro is simple: Sell products and increase conversion rates. One of the main things I learned from my time as a CRO was the importance of friction.
The concept of business friction isn’t new: It’s anything that prevents or dissuades customers from buying your products or services. For customers, friction can be long wait times on hold, products that are out of stock or a bad experience with a company’s website. And friction is just as big an impediment to business transactions as it is to consumers. - BizJournals.com
 Project Successful")
Simply put, once your Customer Experience (CX) is high-friction, the conversion rate (likelihood of a successful outcome) will drop.
If the Implementation of Robust Data Modeling is our conversion goal, then the Implementation Friction is any hurdle that stands in the way of that outcome and our stakeholders saying ‘yes.’ The larger the barrier, the more unlikely it is any large-scale data project will land. Here are some of the largest friction points to data reformation (modeling included) I’ve observed.
Educational Friction: In order to even start the process of improving your data model or architecture you must read a 300+ page book. Not only that but multiple members of your team must read it also (and hopefully some internal customers as well).
Cultural Friction: If you are in a fast-moving engineering org, not only do you have to convince your data-org to implement the data reformation, but you also have to convince your customers, their managers, and the executives, each of which has their own priorities and goals. With every additional stakeholder, the likelihood of success declines.
Market Friction: Try implementing your shiny new data effort when the business lost $100M in a quarter. Whoops. The business is going to be inherently resistant to any non $$$ generating efforts if the balance-sheet is less than ideal.
Maintenance Friction: How will upkeep work in this new model? Do you need a team of 10? Will there need to be embedded BI Engineers on every pod? Do data scientists need to learn modeling? The larger the cost to maintain a new system, the more likely it is people will say no.
Time-To-Value Friction: Is your massive data refactor going to take a year plus until teams start getting deriving value from your work? In the era of Agile, this just isn’t good enough anymore. If the same resources could be deployed on product enhancements and can deliver tangible impact earlier executives will follow the money every time.
As an industry, data professionals need to begin taking the concept of friction seriously. Data consumers are our customers. We are hired to serve their needs. If they are unwilling to adopt a robust new architecture complete with modeling and governance then either A.) We haven’t sold it well enough or B.) The implementation friction is far too high. Righteous indignation does not produce better outcomes. The path to success is to orient our thinking towards #CustomersFirst - understand their pain, their challenges, their priorities, and invest in solutions that make adoption trivial.
Takeaway: In order for data modeling to be prioritized and invested in, it must be simple to adopt, with minimal disruptions, and require a step-stool style educational curve: More complexity requires deeper data knowledge, but more simplistic models are easy for anyone to manage on their own while delivering concrete business value. Implementation Friction must be extremely low in order to promote wide-spread cultural change.
The Bottom Line: Is Data Modeling Dead?
Yes and no.
In the current incarnation of the Modern Data Stack, Data Modeling is dead, buried 20 feet underground and entombed in concrete. Sayonara. Agile, ELT, engineering-lead data efforts, and high implementation friction have rung the death knell for Data Modeling.
That being said, Data Modeling can’t afford to die. While businesses may reap the rewards of speed in the short term, in the long run they will crash headfirst into a brick wall. The complexity of the Warehouse will spiral leaving data consumers spending 50%+ of their time navigating an impenetrable maze of data instead of delivering real value. Cloud Data Warehouse costs will increase dramatically with query complexity and the maintenance burden of supporting a Data Swamp will grow out of proportion with product needs.
Data Modeling needs a v2. And I have some ideas…
In Pt. 2 of this post, we’ll be diving into exactly that. How do we resurrect Data Modeling in a way that’s low friction, Agile, and can be managed by engineering/product teams with no data engineering presence in the loop. If you liked the article, Stay tuned, subscribe, and share. I’d very much appreciate the support!
Not responding on LinkedIn, because I need to be careful what I share.
"Modern" data modelling tends to only encompass analytical modelling. Even then, there isn't always a clear demarcation between a system model, a process model, a dimensional model, or an aggregation model. It's all just a hodgepodge of whatever gets metrics the fastest. This tends to depend a LOT on the accessibility and normalization form of a given application.
Moreover, analytical workloads and operational/integration workloads are also extremely different, and the storage/access patterns for each SHOULD be different. Reverse ETL is a just a messier, less performant implementation of MDM or integration middleware.
Also - business process owners are trending AWAY from using data-enforced standards for declaring their business processes. Microservice data producers often don't even use something declarative to model their processes, instead they make "archi-toons." But there's a whole universe of standards that solidified over 20 years ago and covers everything from hardware design to service modelling:
https://www.omg.org/about/omg-standards-introduction.htm
The biggest opportunity, in my mind - is a system with a killer UX that enables business process owners to describe their process using a mix of behavior and artifact assets. Process models could have links to system level models declared in one of those standards, as well as to more rarefied/groomed models that share the same business logic for both ODS/developer-services and analytical/metadata systems. These inter-relations, and the inter-relations between models could collectively could be kept in a knowledge-graph - with both LDP and RDF aspects.
There are tools out there that offer 2/3 of this, but nothing out there that unifies a EAM stack with a metadata system and analytical modelling tools. There's also very little in the way of a replacement convention to dimensional models in regards to allowing model-driven time-travel. There needs to be a invigoration of modelling standards for the config-as-code era, with a really sexy UX that brings information workers to the table. Every vendor and their mom will claim to have all this, but it will be readily clear when the real data-messiah system comes out...
The real problem started with the decline of data ownership by the business stakeholders. The moment that data ownership is pseudo owned by IT, because they are the only one who understand how to fetch that data, this began a snow ball effect that culminated to today's data modelling reality.
You have to go back to when we are using filing cabinets and folders to store data, which is the height of data ownership, to understand how much decline happened to data ownership. The business stakeholders even have the actual physical keys to these filing cabinets. Twice removed these stakeholders began to rely on IT to pseudo apply ownership privilege and responsibility on data but we all know that their focus is on technology and application not data.
Business stakeholders need to be informed that they need to hold the reigns of their data again, so it represent business reality the closest possible way, adhering to all their business strategic values. The applications should conform to the data not the data conform to these applications. Then these business stakeholders would rely on these data models once more as a reliable and indispensable interface ("keys") to enforce, apply and practice their data ownership on their data.