
The Consumer-Defined Data Contract
Why Producer-Centric Contracts (Can) Fail

Note from Chad: 👋 Hi folks, thanks for reading my newsletter! My name is Chad Sanderson, and I write about data products, data contracts, data modeling, and the future of data engineering and data architecture. I’ve been hard at work building Gable these last few months, but today we’re talking about the data contracts and some recommendations to super-charge adoption, so strap in. As always, I‘d love a follow and share if you find it valuable.
While data contracts are not new, our modern federated implementation leveraging schema registries and CI/CD checks has much less organizational overhead than hand-written data-SLA documents. However, despite being excited that teams are beginning to adopt the concept en masse, I have been getting the sinking feeling that somewhere along the way a message was lost: “Producer-defined data contracts do not work.”
Or rather, it’s less that they don’t work, and more that what is required for a successful producer-defined data contract implementation often does not align with the organizational maturity of the business.
To begin, what do I mean by a producer-defined data contract?
In the same way microservices and product APIs are owned by application developers and back-end engineers, we assume that data contracts should be owned by the team writing data-generating code. The final API spec that data producers create and maintain is called the producer-defined contract.
The spec includes schema, business logic, SLAs, and any other constraints or expectations of the data. The producer acts as a data vendor maintaining the spec and ensuring their data is discoverable through a marketplace or catalog. Each contract should be enforced as close to the production code as possible through integration tests, code review, and monitoring.

The theory is that by encouraging data producers to define their APIs, businesses solve a problem that stems from a lack of explicit ownership. Data producers treat their data as first-class citizens, downstream consumers leverage trustworthy data, and everyone goes home happy.
The wrinkle is that this theory very rarely matches reality.
After speaking to dozens of companies that have implemented producer-defined data contracts, while it is an order of magnitude better than what existed before, companies are still rife with data quality issues and poor change management processes. The reason is embarrassingly straightforward:
If data producers don’t understand how downstream teams are using their data or the expectations they have of it, how can they vend data that consumers want/need?
Here is a simple example:
Imagine a MySQL database that generates a record anytime new customer orders are logged into a ticketing system. The table has several properties useful for analytics such as order price, applied discounts, and so on.
The software engineering team is asked to create a data contract for the database. They settle on a clear schema definition for some of the core components of the table (primary keys, foreign keys, and a few other values) and then call it a day. However, multiple problems then begin to emerge:
Regular NULL records in the orderID field cause accounting errors
There is an expected relationship between orders and users (owned by a different microservice team). When this cardinality is not enforced downstream ML models run into serious issues
Different downstream teams have unique latency expectations. The dashboarding team expects data every week, while the AI team expects it every day
When software engineers run into issues that require a contract update, they simply make the change without telling anyone and break every consumer downstream
We quickly wind up in a position where even with contracts we are back to square 1: endless data quality issues that primarily stem from a lack of understanding of who is using which data and for what.
In product development, software engineers are not responsible for talking to users, understanding their pain points, or defining the requirements and user stories for a new feature. That role is undertaken by product managers or UX designers - customer-facing specialists who deeply understand the use case and ultimately the end user which drives feature design.
Imagine what would happen if engineering teams that never interacted with a customer were responsible for creating the requirements for customer-facing APIs. There would be chaos! The customer wouldn’t get what they needed, thus rendering the work useless and low quality.
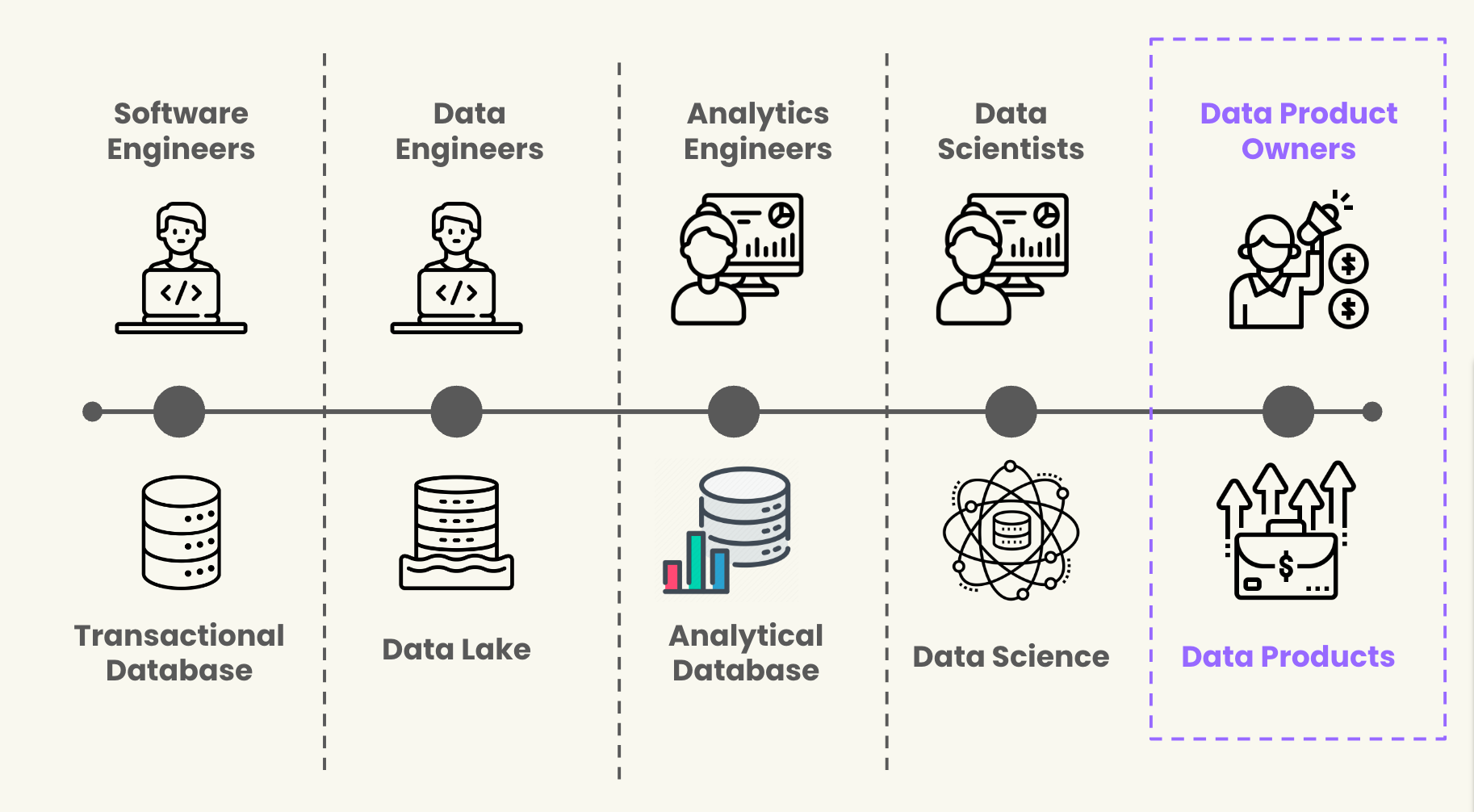
Unlike software engineering assets which are built-for-purpose, most data assets are recycled from existing 1st or 3rd party sources. These datasets are then copied and transformed into a pipeline which may have a wide variety of stakeholders as the data moves from source to its final destination. Because data products are the result of weeks, months, or years of iteration, the likelihood a software engineer who maintains a transactional system will create reasonable quality expectations for a data product they have never seen before and a customer they never interact with is unlikely.
In the same way, the initial data requirements (contract) must be defined by the team with the use cases: consumers. An application developer will never comprehensively understand how data downstream is being used, nor will they fully understand the constraints on data that might be necessary for certain use cases and not others. They will have no concept of which SLAs are useful and which are meaningless. They will not understand how the data model needs to evolve (or how it should have been originally defined). They will have no grasp of how data is replicated across multiple services and where strong relationships must be built between owning producer teams. They won’t understand which data is necessary to be under contract and which isn’t.
A data contract only has value in the context of the use case it supports.
In the same way that a software API only adds value in the context of the application it is designed to serve, the data API only has value in the context of the data product.

Data product is a term that has many different definitions. I prefer looking to our software engineering counterparts for directional guidance. A software product is the sum of many engineering systems organized to serve an explicit business need. Products have interfaces (APIs, User interfaces) and backends. In the same way, a data product is the sum of data components that are organized to serve a business need.
A dashboard is a data product. It is the sum of many components such as visualizations, queries, and a data pipeline. The interface: a drag-and-drop editor, charts, and data tables. The back-end: data pipeline and data sources. This framing rings true for a model’s training set, embedded data products, or other data applications. The data contract should be built in service of these products, not the other way around.
This is the consumer-defined data contract. The consumer-defined contract is created by the owners of data applications, with requirements derived from their needs and use cases. While it contains the same information as the producer-defined contract, it is implemented primarily to draw awareness to the request and inform data producers when new expectations and dependencies exist on the data they maintain. We will cover the process of drawing awareness of consumer needs in more detail below.
Why not just put everything under contract?
I am often asked whether all data sources should be put under contract. This is a gut reaction to the widespread nature of low-quality data in most data ecosystems. Data engineers are so overwhelmed with DQ issues that a shotgun-style approach to code-based data governance is very appealing.
A common proposal is to require data producers to create contracts before emitting data to an analytical environment. This forces data producers to create contracts in advance and treat the analytical data they emit as a part of their database implementation or event-driven architecture.

“Never, ever, think about something else when you should be thinking about the power of incentives.”
— Charlie Munger
However, consider the implications of such a system. An engineer who is required to put everything under contract now has to maintain schemas, business logic, and SLAs for data that could theoretically have no use case. This has little benefit to the engineer and will come at the expense of significantly slowing developer productivity - a cardinal sin in fast-moving engineering organizations. As an application developer, are you incentivized to create as many thoughtful contracts as possible, or will you emit as little data to the analytical environment as you can get away with? In my experience, the answer is the latter!
Data teams require the ability to rapidly experiment on data that may or may not be useful. This experimentation is critical to the workflow of data scientists and analysts. After a dataset or query has been generated that provides production-grade business utility, only then does the need for data quality, dependency management, and contracts emerge. Again, we find ourselves circling back to the necessity of data products driving contract definition.
To build a sustainable system of code-based governance, data teams need to provide both a carrot and a stick to upstream engineering teams. Data contracts can be adopted when they are perceived as useful, not solely as a cost to developer speed or additional ‘work’ the engineer has to take on. Unless there is accountability at the producer level for the data products, upstream teams will always lack the buy-in required to organically maintain contract ownership moving forward.

I prefer to think about data contract adoption as a 3-phrase maturity curve. Jumping straight to contract ownership without the groundwork of awareness and collaboration being laid in advance to make the adoption scalable and well-received is likely to result in disaster.
Phase 1: Awareness (The Consumer-Defined Contract)
In the Awareness phase, data producers must understand that changes they make to data will harm consumers. Most data producers are operating in a black box regarding the data they emit. They don’t want to cause outages, but without any context provided pre-deployment, it is incredibly challenging to do so.
Even without the implementation of a producer-defined data contract, producers should still be aware of when they are making code changes that will affect data, exactly what those changes will impact, and who they should speak to before shipping. This pre-deployment awareness drives accountability and most importantly - conversation.

Phase 2: Collaboration
Once a data producer has some understanding of how their changes will impact others in the organization, they are faced with a set of choices. A.) Make the breaking change and knowingly cause an outage or B.) Communicate with the data consumers that the change is coming. The second option is better for a wide variety of reasons that should be obvious!
This resolves most problems for data consumers. They are informed in advance before breaking changes are made, have plenty of time to prepare, and can potentially delay or deter software engineers’ deployment by advocating for their own use cases of the data. This sort of change management functions in a similar way to pull requests. Just as an engineer asks for feedback about their code change, with a consumer-driven contract, they may also “ask” for feedback about their change to data.
Note: It can’t be stressed enough the importance of this collaboration happening pre-deployment driven by context. Once code has been merged it is no longer the responsibility of the engineer. You can’t be accountable for a change you were never informed about!
Phase 3: Contract Ownership
This shift-left towards data accountability resolves problems but also creates new challenges. Consider you are a software engineer who regularly ships code changes that affect your database. Every time you do so, you see that there are dozens of downstream consumers, each with critical dependencies on your data. It’s not impossible to simply communicate with them which changes are coming, but to do that for each consumer is incredibly time-consuming! Not only that, but it turns out certain consumers have taken dependencies on data that they shouldn’t be, or are misusing data that you provide.
At this point, it is beneficial for producers to define a data contract, for the following reasons:
Producers now understand the use cases and consumers/customers
Producers can explicitly define which fields to make accessible to the broader organization
Producers have clear processes in place for change management, contract versioning, and contract evolution
Data producers clearly understand how changes to their data impact others, have a clear sense of accountability for their data, and can apply data contracts where they matter most to the business. In short, consumer-defined contracts create problem visibility, and visibility creates culture change.
Summary
The outcome of a producer-defined system may seem like a great step in the direction, but ultimately still fails unless there is clear top-to-bottom buy-in:
Producers will change contracts however they need to when shipping new features as they have no accountability for data outages downstream
Consumers have virtually no input on these contracts, resulting in their use cases not being satisfied
Producers must take ownership of all data they maintain, even if it has no value to any consumer (this can’t scale)
Meanwhile, starting with consumer-defined contracts as a mechanism to generate awareness leads to exceptional short and long-term benefits:
Contracts can be requested by the owners of downstream data products that understand and use the data for their daily work
Producers can be alerted when they are impacting data products, driving change communication without strictly defined ownership
Producer-centric data contracts become a net benefit, reducing communication costs and safeguarding producers from causing outages
As a disclaimer, with the amount of engineering buy-in, technology, and process management starting with producer-defined contracts CAN work, but it is challenging to maintain at scale without tremendously simple implementation and scaling capacity.
I hope you enjoyed the read! If you want to talk more about data contracts feel free to shoot me a message on LinkedIn, or check out how we’re rolling out contracts at scale (both producer and consumer-defined) at Gable.ai. Finally, my friend and incredible engineer Ricommini launched a blog recently called Materialized View that you should check out if you’re looking for new and interesting reads. See you next time!
-Chad
Ugh, preach. I am in the process of modernizing data pipelines and contracts at a major retailer, and the whole “business isn’t ready to change” is a big forcing function on the data contract.
Would love to chat more about it since it seems you have been doing this longer than me.